本页面解释了 Spark Connect 架构、Spark Connect 的优势以及如何升级到 Spark Connect。
让我们从高层次上探索 Spark Connect 的架构开始。
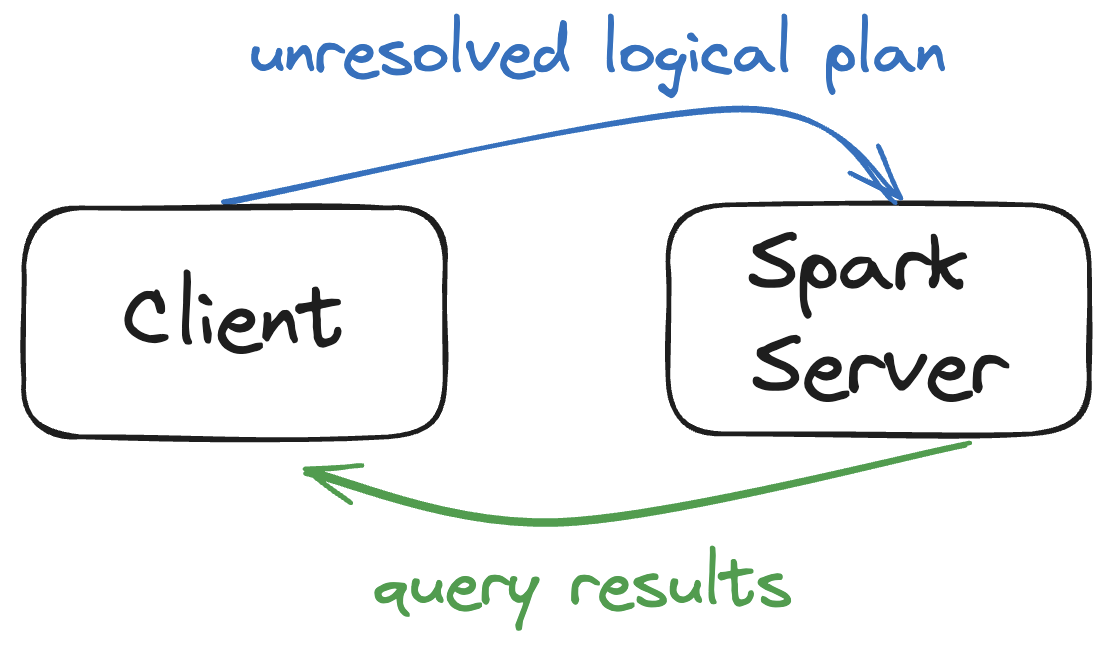
高层次 Spark Connect 架构
Spark Connect 是一种协议,它规定了客户端应用程序如何与远程 Spark 服务器通信。实现 Spark Connect 协议的客户端可以连接并向远程 Spark 服务器发出请求,这与客户端应用程序使用 JDBC 驱动程序连接数据库的方式非常相似——查询 spark.table("some_table").limit(5) 应该简单地返回结果。这种架构为最终用户提供了极佳的开发体验。
以下是 Spark Connect 的高层次工作方式
- 客户端与 Spark 服务器之间建立连接
- 客户端将 DataFrame 查询转换为未解析的逻辑计划,该计划描述了操作的意图而非执行方式
- 未解析的逻辑计划被编码并发送到 Spark 服务器
- Spark 服务器优化并运行查询
- Spark 服务器将结果返回给客户端
让我们更详细地了解这些步骤,以便更好地理解 Spark Connect 的内部工作原理。
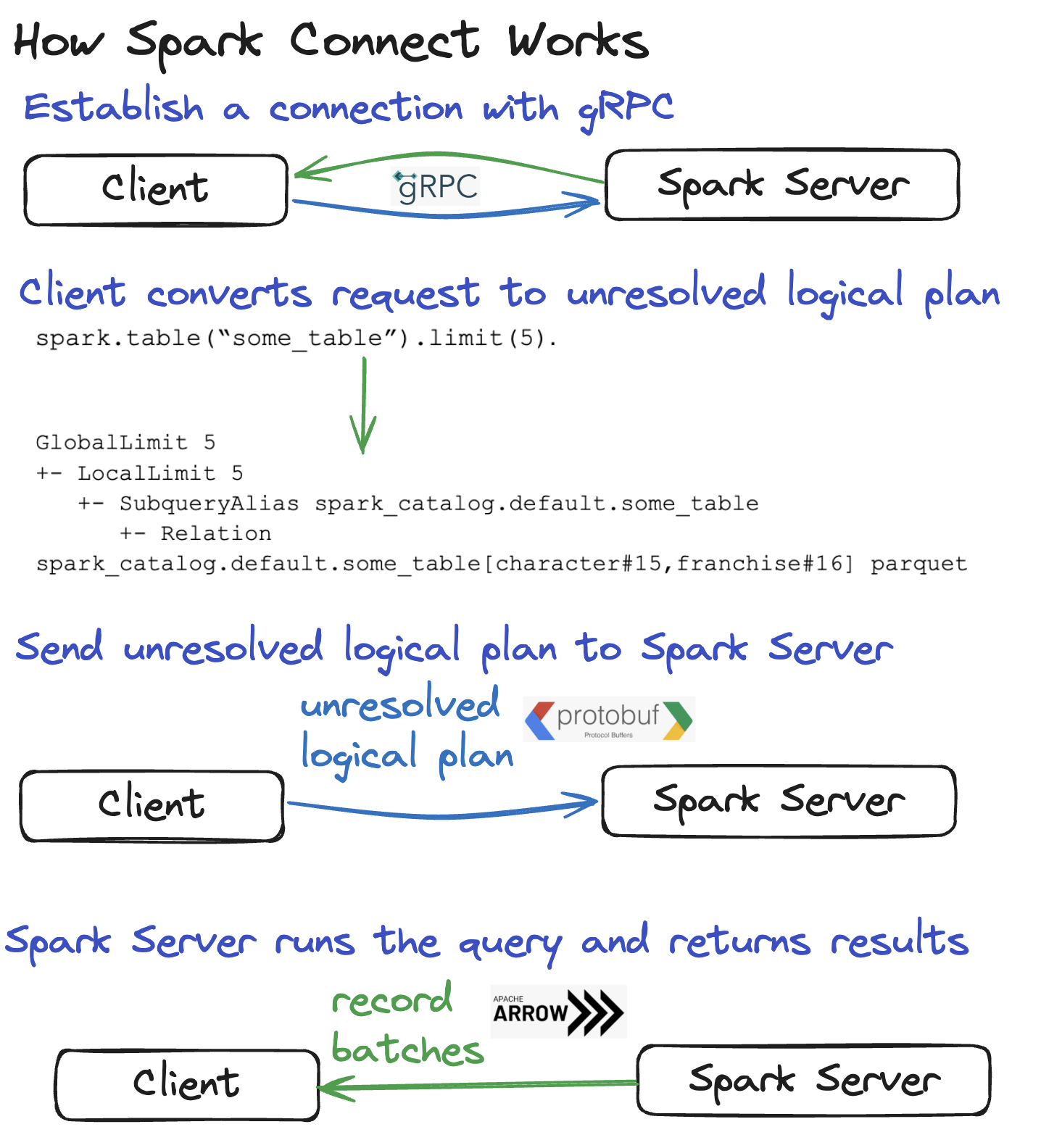
在客户端和 Spark 服务器之间建立连接
Spark Connect 的网络通信使用 gRPC 框架。
gRPC 性能高且与语言无关,这使得 Spark Connect 具有可移植性。
将 DataFrame 查询转换为未解析的逻辑计划
客户端解析 DataFrame 查询并将其转换为未解析的逻辑计划。
假设您有以下 DataFrame 查询:spark.table("some_table").limit(5)。
这是该查询的未解析逻辑计划
== Parsed Logical Plan ==
GlobalLimit 5
+- LocalLimit 5
+- SubqueryAlias spark_catalog.default.some_table
+- UnresolvedRelation spark_catalog.default.some_table
客户端负责创建未解析的逻辑计划并将其传递给 Spark 服务器执行。
将未解析的逻辑计划发送到 Spark 服务器
未解析的逻辑计划必须被序列化,以便可以通过网络发送。Spark Connect 使用 Protocol Buffers,它是一种“与语言无关、与平台无关的可扩展机制,用于序列化结构化数据”。
客户端和 Spark 服务器必须能够使用像 Protocol Buffers 这样的语言中立格式进行通信,因为它们可能使用不同的编程语言或不同的软件版本。
现在让我们看看 Spark 服务器如何执行查询。
在 Spark 服务器上执行查询
Spark 服务器接收未解析的逻辑计划(一旦 Protocol Buffer 被反序列化),并像处理任何其他查询一样对其进行分析、优化和执行。
Spark 在执行查询之前会对未解析的逻辑计划进行许多优化。所有这些优化都发生在 Spark 服务器上,并且独立于客户端应用程序。
Spark Connect 允许您利用 Spark 强大的查询优化能力,即使客户端不依赖于 Spark 或 JVM。
将结果发送回客户端
Spark 服务器在执行查询后将结果发送回客户端。
结果以 Apache Arrow 记录批次的形式发送到客户端。单个记录批次包含许多行数据。
完整的结果以记录批次的部分块流式传输到客户端,而不是一次性全部传输。将结果从 Spark 服务器流式传输到客户端可以防止因请求过大导致的内存问题。
以下是 Spark Connect 工作原理的图片回顾
Spark Connect 的优势
现在让我们将注意力转向 Spark Connect 架构的优势。
Spark Connect 工作负载更易于维护
当您不使用 Spark Connect 时,客户端和 Spark Driver 必须运行相同的软件版本。它们需要相同的 Java、Scala 和其他依赖版本。假设您在本地机器上开发一个 Spark 项目,将其打包为 JAR 文件,并将其部署到云端以在生产数据集上运行。您需要在本地机器上使用与云端相同的依赖项构建 JAR 文件。如果您使用 Scala 2.13 编译 JAR 文件,那么您也必须使用为 Scala 2.13 编译的 Spark JAR 来配置集群。
假设您正在使用 Scala 2.12 构建您的 JAR,并且您的云提供商发布了使用 Scala 2.13 构建的新运行时。当您不使用 Spark Connect 时,您需要在本地更新您的项目,这可能具有挑战性。例如,当您将项目更新到 Scala 2.13 时,您还必须将所有项目依赖项(和传递依赖项)升级到 Scala 2.13。如果其中一些 JAR 文件不存在,您就无法升级。
相比之下,Spark Connect 解耦了客户端和 Spark Driver,因此您可以更新 Spark Driver,包括服务器端依赖项,而无需更新客户端。这使得 Spark 项目更容易维护。特别是对于纯 Python 工作负载,将 Python 从客户端上的 Java 依赖中解耦,改善了 Apache Spark 的整体用户体验。
Spark Connect 允许您使用非 JVM 语言构建 Spark Connect 客户端
Spark Connect 解耦了客户端和 Spark Driver,因此您可以用任何语言编写 Spark Connect 客户端。以下是一些不依赖 Java/Scala 的 Spark Connect 客户端
- Spark Connect Python
- Spark Connect Go
- Spark Connect Rust (第三方项目)
- Spark Connect dotnet (第三方项目)
例如,用于 Golang 的 Apache Spark Connect 客户端 spark-connect-go 实现了 Spark Connect 协议,并且不依赖 Java。您可以使用此 Spark Connect 客户端使用 Go 开发 Spark 应用程序,而无需安装 Java 或 Spark。
以下是如何使用 Go 编程语言通过 spark-connect-go 执行查询
spark, _ := sql.SparkSession.Builder.Remote(remote).Build()
df, _ := spark.Sql("select * from my_cool_table where age > 42")
df.Show(100, false)
当调用 df.Show() 时,spark-connect-go 会将查询处理成未解析的逻辑计划,并将其发送到 Spark Driver 执行。
spark-connect-go 是 Spark Connect 解耦特性如何带来更好最终用户体验的绝佳例子。
Go 并不是唯一将受益于这种架构的语言。
Spark Connect 允许更好的远程开发和测试
Spark Connect 还允许您在远程集群上的文本编辑器中嵌入 Spark,而无需 SSH(“远程开发”)。
当您不使用 Spark Connect 时,在文本编辑器中嵌入 Spark 需要在本地运行 Spark Session 或通过 SSH 连接到远程 Spark Driver。
Spark Connect 允许您通过完全嵌入在文本编辑器中的连接连接到远程 Spark Driver,而无需 SSH。这为用户在远程 Spark 集群上使用 VS Code 等文本编辑器开发代码时提供了更好的体验。
使用 Spark Connect,从本地 Spark Session 切换到远程 Spark Session 很容易——只需更改连接字符串即可。
Spark Connect 使调试更简单
Spark Connect 允许您将 IntelliJ 等文本编辑器连接到远程 Spark 集群,并通过调试器逐步执行代码。您可以像在本地机器上调试测试数据集一样,调试在生产数据集上运行的应用程序。这为您提供了极佳的开发体验,尤其是当您想要利用 IDE 中内置的高质量调试工具时。
Spark JVM 不允许这种调试体验,因为它没有与文本编辑器完全集成。Spark Connect 允许您在文本编辑器中构建紧密集成,为远程 Spark 工作流提供出色的调试体验。通过简单地切换 Spark Connect 会话的连接字符串,可以轻松配置客户端以在不同的执行环境中运行测试,而无需部署复杂的 Spark 应用程序。
Spark Connect 更稳定
由于利用 Spark Connect 的客户端应用程序的解耦特性,客户端的故障现在与 Spark Driver 解耦。这意味着当客户端应用程序失败时,其故障模式完全独立于其他应用程序,并且不会影响可能继续服务其他客户端应用程序的正在运行的 Spark Driver。
升级到 Spark Connect
Spark Connect 不支持所有 Spark JVM API。例如,Spark JVM 具有一些用户利用的私有方法,用于在 Spark 集群上执行任意 Java 代码。Spark Connect 显然无法支持这些方法,因为 Spark Connect 客户端不一定运行 Java!
请查阅从 Spark JVM 迁移到 Spark Connect 的指南,了解如何编写与 Spark Connect 兼容的代码。此外,请查阅如何构建 Spark Connect 自定义扩展以了解如何使用专用逻辑。
结论
Spark Connect 是一种在生产环境中运行 Spark 的更好架构。它更灵活,更易于维护,并提供更好的开发体验。
将一些 Spark JVM 代码库迁移到 Spark Connect 很容易,但对于其他代码库来说,迁移具有挑战性。利用 RDD API 或使用私有 Spark JVM 函数的代码库更难迁移。
然而,从 Spark JVM 迁移到 Spark Connect 是一次性成本,因此一旦迁移,您将享受到所有好处。
最新消息
- Spark 3.5.6 发布 (2025 年 5 月 29 日)
- Spark 4.0.0 发布 (2025 年 5 月 23 日)
- Spark 3.5.5 发布 (2025 年 2 月 27 日)
- Spark 3.5.4 发布 (2024 年 12 月 20 日)
