测试覆盖率
Apache Spark 社区利用各种资源来维护社区测试覆盖率。
GitHub Actions
GitHub Actions 在 Ubuntu 22.04 上提供以下功能。
Apache Spark 4
- Scala 2.13 SBT 构建(使用 Java 17)
- Scala 2.13 Maven 构建(使用 Java 17/21)
- Java/Scala/Python/R 单元测试(使用 Java 17/Scala 2.13/SBT)
- TPC-DS 基准测试,规模因子为 1
- JDBC Docker 集成测试
- Kubernetes 集成测试
- 每日 Java/Scala/Python/R 单元测试(使用 Java 21 和 Scala 2.13/SBT)
Apache Spark 3
- Scala 2.12 SBT 构建(使用 Java 8)
- Scala 2.12 Maven 构建(使用 Java 11/17)
- Java/Scala/Python/R 单元测试(使用 Java 8/Scala 2.12/SBT)
- Kubernetes 集成测试
- 每日 Java/Scala/Python/R 单元测试(使用 Java 8 和 Scala 2.13/SBT)
- 每日 JDBC Docker 集成测试(使用 Java 8 和 Scala 2.13/SBT)
- 每日 TPC-DS 基准测试,规模因子为 1(使用 Java 8 和 Scala 2.12/SBT)
实用的开发者工具
减少构建时间
SBT:避免重新创建 assembly JAR
Spark 的默认构建策略是组装一个包含所有依赖项的 JAR 包。这在迭代开发时可能会很麻烦。在本地开发时,可以先创建一个包含所有 Spark 依赖项的 assembly JAR 包,然后在进行更改时只重新打包 Spark 本身。
$ build/sbt clean package
$ ./bin/spark-shell
$ export SPARK_PREPEND_CLASSES=true
$ ./bin/spark-shell # Now it's using compiled classes
# ... do some local development ... #
$ build/sbt compile
$ unset SPARK_PREPEND_CLASSES
$ ./bin/spark-shell
# You can also use ~ to let sbt do incremental builds on file changes without running a new sbt session every time
$ build/sbt ~compile
单独构建子模块
例如,您可以使用以下命令构建 Spark Core 模块
$ # sbt
$ build/sbt
> project core
> package
$ # or you can build the spark-core module with sbt directly using:
$ build/sbt core/package
$ # Maven
$ build/mvn package -DskipTests -pl core
运行单个测试
在本地开发时,通常方便运行单个测试或少数几个测试,而不是运行整个测试套件。
使用 SBT 进行测试
运行单个测试最快的方法是使用 sbt 控制台。保持 sbt 控制台打开,并根据需要使用它重新运行测试是最快的。例如,要运行特定项目(例如 core)中的所有测试
$ build/sbt
> project core
> test
您可以使用 testOnly 命令运行单个测试套件。例如,要运行 DAGSchedulerSuite
> testOnly org.apache.spark.scheduler.DAGSchedulerSuite
testOnly 命令接受通配符;例如,您也可以使用以下命令运行 DAGSchedulerSuite
> testOnly *DAGSchedulerSuite
或者您可以运行 scheduler 包中的所有测试
> testOnly org.apache.spark.scheduler.*
如果您想在 DAGSchedulerSuite 中只运行一个测试,例如,名称中包含“SPARK-12345”的测试,您可以在 sbt 控制台中运行以下命令
> testOnly *DAGSchedulerSuite -- -z "SPARK-12345"
如果您愿意,可以在命令行上运行所有这些命令(但这会比使用打开的控制台运行测试慢)。为此,您需要将 testOnly 和后续参数用引号括起来
$ build/sbt "core/testOnly *DAGSchedulerSuite -- -z SPARK-12345"
有关如何使用 sbt 运行单个测试的更多信息,请参阅 sbt 文档。
使用 Maven 进行测试
使用 Maven,您可以使用 -DwildcardSuites 标志运行单个 Scala 测试
build/mvn -Dtest=none -DwildcardSuites=org.apache.spark.scheduler.DAGSchedulerSuite test
您需要 -Dtest=none 以避免运行 Java 测试。有关 ScalaTest Maven 插件的更多信息,请参阅 ScalaTest 文档。
要运行单个 Java 测试,您可以使用 -Dtest 标志
build/mvn test -DwildcardSuites=none -Dtest=org.apache.spark.streaming.JavaAPISuite test
测试 PySpark
要运行单个 PySpark 测试,您可以使用 python 目录下的 run-tests 脚本。测试用例位于每个 PySpark 包下的 tests 包中。请注意,如果您在 Apache Spark 的 Scala 或 Python 侧添加了更改,则在运行 PySpark 测试之前需要手动再次构建 Apache Spark 以应用更改。运行 PySpark 测试脚本不会自动构建它。
此外,请注意在 macOS High Serria+ 上使用 PySpark 存在一个持续性问题。OBJC_DISABLE_INITIALIZE_FORK_SAFETY 必须设置为 YES 才能运行部分测试。有关更多详细信息,请参阅 PySpark 问题 和 Python 问题。
在特定模块中运行测试用例
$ python/run-tests --testnames pyspark.sql.tests.test_arrow
在特定类中运行测试用例
$ python/run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests'
在特定类中运行单个测试用例
$ python/run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion'
您也可以在特定模块中运行 doctests
$ python/run-tests --testnames pyspark.sql.dataframe
最后,在同一位置还有一个名为 run-tests-with-coverage 的脚本,它为 PySpark 测试生成覆盖率报告。它接受与 run-tests 相同的参数。
$ python/run-tests-with-coverage --testnames pyspark.sql.tests.test_arrow --python-executables=python
...
Name Stmts Miss Branch BrPart Cover
-------------------------------------------------------------------
pyspark/__init__.py 42 4 8 2 84%
pyspark/_globals.py 16 3 4 2 75%
...
Generating HTML files for PySpark coverage under /.../spark/python/test_coverage/htmlcov
您可以通过 /.../spark/python/test_coverage/htmlcov 下的 HTML 文件直观地查看覆盖率报告。
请通过 python/run-tests[-with-coverage] --help 查看其他可用选项。
测试 K8S
虽然 GitHub Actions 提供了 K8s 单元测试和集成测试覆盖率,但您可以在本地运行它们。例如,Volcano 批处理调度器集成测试需要手动完成。详情请参阅集成测试文档。
https://github.com/apache/spark/blob/master/resource-managers/kubernetes/integration-tests/README.md
运行 Docker 集成测试
Docker 集成测试由 GitHub Actions 覆盖。但是,您可以在本地运行它以加快开发和测试。详情请参阅 Docker 集成测试文档。
使用 GitHub Actions 工作流进行测试
Apache Spark 利用 GitHub Actions 实现持续集成和广泛的自动化。Apache Spark 仓库提供了多个 GitHub Actions 工作流,供开发者在创建拉取请求之前运行。
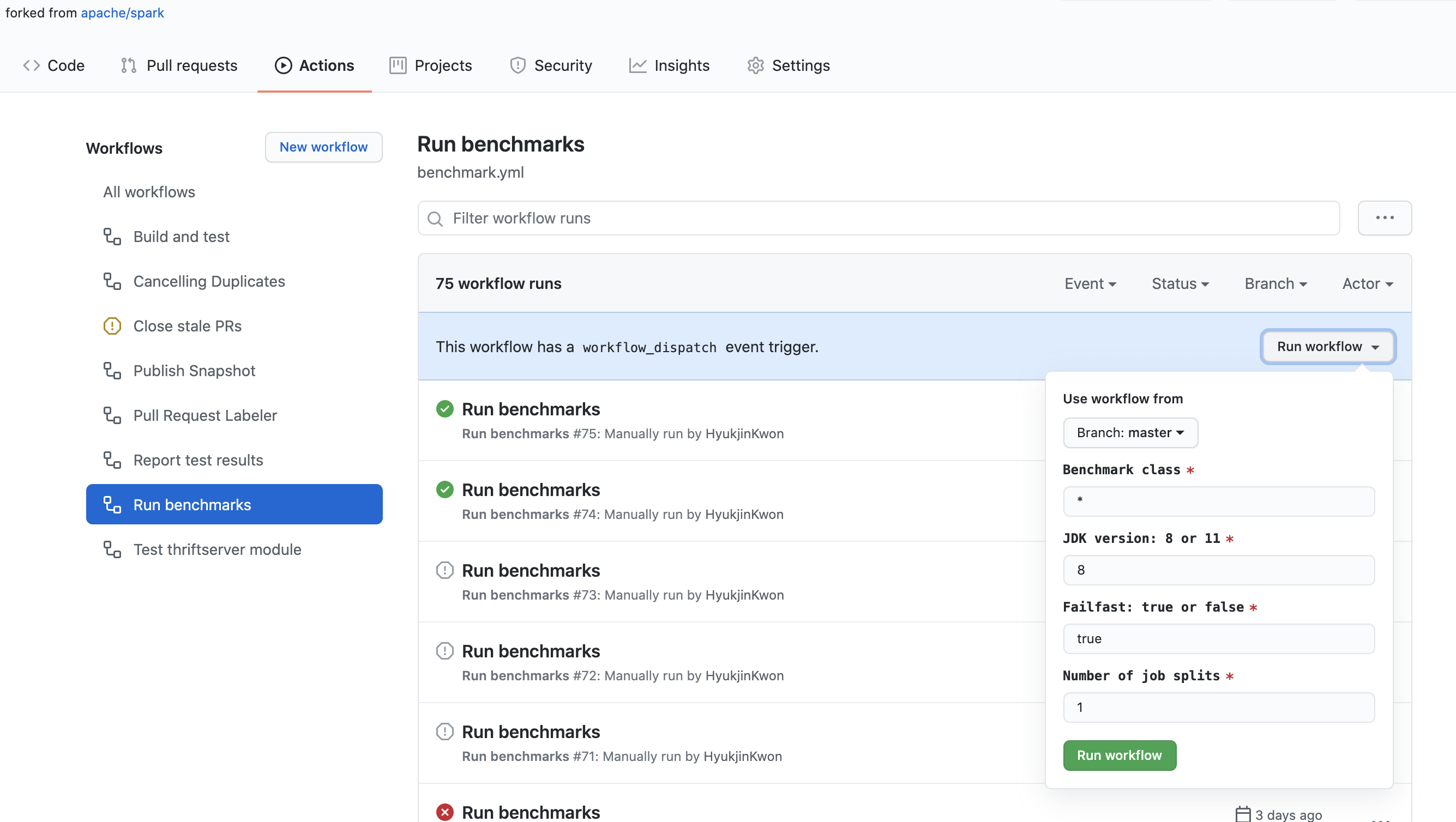
在您的 Fork 仓库中运行基准测试
Apache Spark 仓库提供了一种在 GitHub Actions 中运行基准测试的简单方法。当您在拉取请求中更新基准测试结果时,建议使用 GitHub Actions 运行和生成基准测试结果,以便在尽可能相同的环境中运行它们。
- 在您的 Fork 仓库中点击“Actions”选项卡。
- 在“All workflows”列表中选择“Run benchmarks”工作流。
- 点击“Run workflow”按钮并按照如下适当填写字段
- 基准测试类:您希望运行的基准测试类。它允许使用 glob 模式。例如,
org.apache.spark.sql.*。 - JDK 版本:您希望运行基准测试的 Java 版本。例如,
11。 - 快速失败:指示您是否希望在基准测试或工作流失败时停止。当设置为
true时,它会立即失败。当设置为false时,无论是否失败,它都会运行所有测试。 - 作业拆分数:它将基准测试作业拆分成指定数量,并并行运行它们。这对于规避 GitHub Actions 中工作流和作业的时间限制特别有用。
- 基准测试类:您希望运行的基准测试类。它允许使用 glob 模式。例如,
- “Run benchmarks”工作流完成后,点击该工作流并在“Artifacts”中下载基准测试结果。
- 进入 Apache Spark 仓库的根目录,解压/解档下载的文件,这将通过适当定位要更新的文件来更新基准测试结果。
ScalaTest 问题
如果运行 ScalaTest 时出现以下错误
An internal error occurred during: "Launching XYZSuite.scala".
java.lang.NullPointerException
这是由于类路径中 Scala 库不正确。要解决此问题
- 右键点击项目
- 选择
Build Path | Configure Build Path 添加库 | Scala 库- 移除
scala-library-2.10.4.jar - lib_managed\jars
如果出现“Could not find resource path for Web UI: org/apache/spark/ui/static”错误,这是由于类路径问题(某些类可能未编译)。要解决此问题,只需从命令行运行一个测试即可
build/sbt "testOnly org.apache.spark.rdd.SortingSuite"
二进制兼容性
为了确保二进制兼容性,Spark 使用 MiMa。
确保二进制兼容性
在处理问题时,在打开拉取请求之前,最好检查您的更改是否引入了二进制不兼容性。
您可以通过运行以下命令来做到这一点
$ dev/mima
MiMa 报告的二进制不兼容性可能如下所示
[error] method this(org.apache.spark.sql.Dataset)Unit in class org.apache.spark.SomeClass does not have a correspondent in current version
[error] filter with: ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.SomeClass.this")
解决二进制不兼容性
如果您认为您的二进制不兼容性是合理的,或者 MiMa 报告了误报(例如,报告的二进制不兼容性是关于非面向用户的 API),您可以通过在 project/MimaExcludes.scala 中添加一个排除项来过滤它们,该排除项包含 MiMa 报告中建议的内容,以及一个包含您正在处理的问题的 JIRA 编号及其标题的注释。
对于上述问题,我们可能会添加以下内容
// [SPARK-zz][CORE] Fix an issue
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.SomeClass.this")否则,您将必须在打开或更新拉取请求之前解决这些不兼容性。通常,MiMa 报告的问题都是不言自明的,并且围绕着您必须添加回来的缺失成员(方法或字段),以便保持二进制兼容性。
检出拉取请求
Git 提供了一种将远程拉取请求获取到您本地仓库的机制。这在本地审查代码或测试补丁时很有用。如果您尚未克隆 Spark Git 仓库,请使用以下命令
$ git clone https://github.com/apache/spark.git
$ cd spark
要启用此功能,您需要配置 git 远程仓库以获取拉取请求数据。通过修改 Spark 目录内的 .git/config 文件来完成此操作。如果您将其命名为其他名称,则远程可能不叫“origin”
[remote "origin"]
url = git@github.com:apache/spark.git
fetch = +refs/heads/*:refs/remotes/origin/*
fetch = +refs/pull/*/head:refs/remotes/origin/pr/* # Add this line
完成此操作后,您可以获取远程拉取请求
# Fetch remote pull requests
$ git fetch origin
# Checkout a remote pull request
$ git checkout origin/pr/112
# Create a local branch from a remote pull request
$ git checkout origin/pr/112 -b new-branch
生成依赖图
$ # sbt
$ build/sbt dependencyTree
$ # Maven
$ build/mvn -DskipTests install
$ build/mvn dependency:tree
组织导入
您可以使用 Aaron Davidson 开发的 IntelliJ Imports Organizer 来帮助您组织代码中的导入。它可以配置为与样式指南中的导入顺序匹配。
格式化代码
要格式化 Scala 代码,请在提交 PR 之前运行以下命令
$ ./dev/scalafmt
默认情况下,此脚本将格式化与 git master 不同的文件。有关更多信息,请参阅 scalafmt 文档,但请使用现有脚本,而不是本地安装的 scalafmt 版本。
IDE 设置
IntelliJ
虽然许多 Spark 开发者在命令行上使用 SBT 或 Maven,但我们最常用的 IDE 是 IntelliJ IDEA。您可以免费获取社区版(Apache 提交者可以获得免费的 IntelliJ Ultimate Edition 许可证),并从 Preferences > Plugins 安装 JetBrains Scala 插件。
为 IntelliJ 创建 Spark 项目
- 下载 IntelliJ 并安装 IntelliJ 的 Scala 插件。
- 转到
File -> Import Project,找到 spark 源目录,然后选择“Maven Project”。 - 在导入向导中,保留默认设置即可。但通常建议启用“Import Maven projects automatically”,因为项目结构的更改将自动更新 IntelliJ 项目。
- 正如 构建 Spark 中所述,某些构建配置需要启用特定的配置文件。上面通过
-P[profile name]启用的相同配置文件可以在导入向导的 Profiles 屏幕上启用。例如,如果为支持 YARN 的 Hadoop 2.7 进行开发,请启用yarn和hadoop-2.7配置文件。这些选择稍后可以通过从 View 菜单访问“Maven Projects”工具窗口并展开 Profiles 部分来更改。
其他提示
- 项目首次编译时,“Rebuild Project”可能会失败,因为生成的源文件未自动生成。尝试点击“Maven Projects”工具窗口中的“Generate Sources and Update Folders For All Projects”按钮,以手动生成这些源文件。
- IntelliJ 中捆绑的 Maven 版本可能不够新,无法用于 Spark。如果发生这种情况,“Generate Sources and Update Folders For All Projects”操作可能会静默失败。请记住重置项目的 Maven 主目录(
Preference -> Build, Execution, Deployment -> Maven -> Maven home directory),使其指向更新的 Maven 安装。您也可以先使用脚本build/mvn构建 Spark。如果脚本找不到足够新的 Maven 安装,它将下载并安装最新版本的 Maven 到build/apache-maven-<version>/文件夹中。 - 一些模块根据 Maven 配置文件(即支持 Scala 2.11 和 2.10,或允许针对不同版本的 Hive 进行交叉构建)具有可插拔的源目录。在某些情况下,IntelliJ 无法正确检测到使用 maven-build-plugin 添加源目录。在这些情况下,您可能需要显式添加源位置才能编译整个项目。如果是这样,请打开“Project Settings”并选择“Modules”。根据您选择的 Maven 配置文件,您可能需要将源文件夹添加到以下模块
- spark-hive:添加 v0.13.1/src/main/scala
- spark-streaming-flume-sink:添加 target\scala-2.11\src_managed\main\compiled_avro
- spark-catalyst:添加 target\scala-2.11\src_managed\main
- 编译可能会失败,并出现类似“scalac: bad option: -P:/home/jakub/.m2/repository/org/scalamacros/paradise_2.10.4/2.0.1/paradise_2.10.4-2.0.1.jar”的错误。如果是这样,请转到 Preferences > Build, Execution, Deployment > Scala Compiler 并清除“Additional compiler options”字段。然后它就可以工作了,尽管当项目重新导入时该选项会再次出现。如果您尝试使用 quasiquotes(例如 sql)构建任何项目,则需要将该 jar 设置为编译器插件(就在“Additional compiler options”下方)。否则您会看到类似以下错误
/Users/irashid/github/spark/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala Error:(147, 9) value q is not a member of StringContext Note: implicit class Evaluate2 is not applicable here because it comes after the application point and it lacks an explicit result type q""" ^
远程调试 Spark
本部分将向您展示如何使用 IntelliJ 远程调试 Spark。
设置远程调试配置
按照Run > Edit Configurations > + > Remote打开默认的远程配置模板: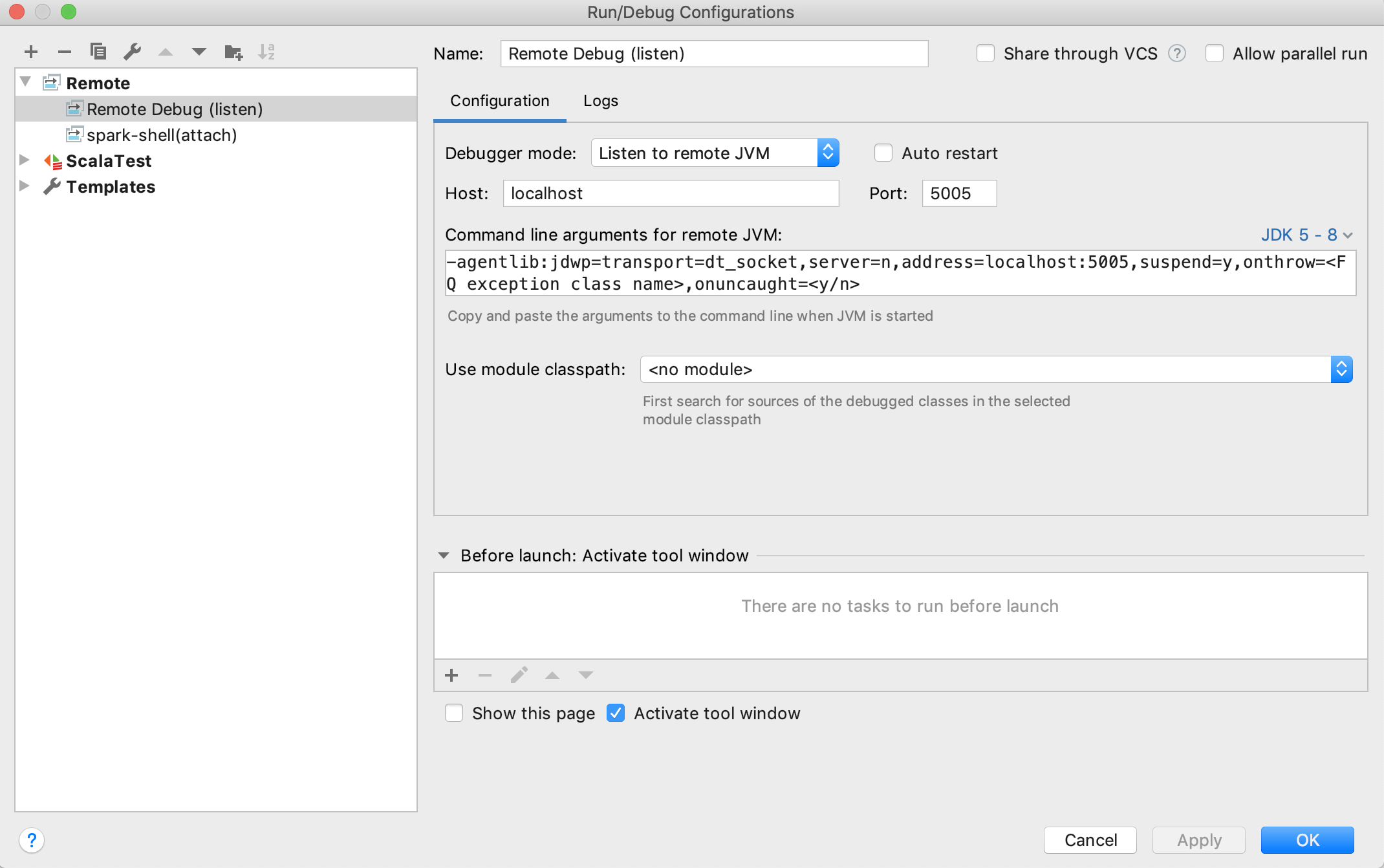
通常,默认值足以使用。请确保您选择 Listen to remote JVM 作为Debugger mode,并选择正确的 JDK 版本以生成适当的Command line arguments for remote JVM。
完成配置并保存后。您可以按照Run > Run > Your_Remote_Debug_Name > Debug来启动远程调试过程并等待 SBT 控制台连接

触发远程调试
一般来说,有 2 个步骤
- 使用上一步中生成的Command line arguments for remote JVM设置 JVM 选项。
- 启动 Spark 执行(SBT 测试、pyspark 测试、spark-shell 等)
以下是使用 SBT 单元测试触发远程调试的示例。
在 SBT 控制台中输入
./build/sbt
切换到目标测试所在的项目,例如
sbt > project core
复制Command line arguments for remote JVM
sbt > set javaOptions in Test += "-agentlib:jdwp=transport=dt_socket,server=n,suspend=n,address=localhost:5005"
使用 IntelliJ 设置断点并使用 SBT 运行测试,例如
sbt > testOnly *SparkContextSuite -- -t "Only one SparkContext may be active at a time"
当您在 IntelliJ 控制台中看到“Connected to the target VM, address: ‘localhost:5005’, transport: ‘socket’”时,表示已成功连接到 IntelliJ。然后,您就可以像往常一样在 IntelliJ 中开始调试了。
要退出远程调试模式(这样您就不必一直启动远程调试器),在项目中使用 SBT 控制台时键入“session clear”。
Eclipse
Eclipse 可用于开发和测试 Spark。以下配置已知可行
- Eclipse Juno
- Scala IDE 4.0
- Scala Test
最简单的方法是从 Scala IDE 下载页面下载 Scala IDE 包。它预装了 ScalaTest。或者,可以使用 Scala IDE 更新站点或 Eclipse Marketplace。
SBT 可以创建 Eclipse .project 和 .classpath 文件。要为每个 Spark 子项目创建这些文件,请使用此命令
sbt/sbt eclipse
要导入特定项目(例如 spark-core),请选择 File | Import | Existing Projects 到 Workspace。不要选择“Copy projects into workspace”。
如果您想在 Scala 2.10 上进行开发,您需要为用于编译 Spark 的确切 Scala 版本配置 Scala 安装。由于 Scala IDE 捆绑了最新版本(目前为 2.10.5 和 2.11.8),您需要在 Eclipse Preferences -> Scala -> Installations 中添加一个,指向您的 Scala 2.10.5 发行版的 lib/ 目录。完成此操作后,选择所有 Spark 项目并右键单击,选择 Scala -> Set Scala Installation 并指向 2.10.5 安装。这应该会清除所有关于无效交叉编译库的错误。现在应该可以成功进行干净构建了。
ScalaTest 可以通过右键单击源文件并选择 Run As | Scala Test 来执行单元测试。
如果出现 Java 内存错误,可能需要增加 Eclipse 安装目录中 eclipse.ini 文件中的设置。根据需要增加以下设置
--launcher.XXMaxPermSize
256M
每夜构建
Spark 每夜发布 master 和维护分支的 Maven SNAPSHOT 版本。要链接到 SNAPSHOT,您需要将 ASF 快照仓库添加到您的构建中。请注意,SNAPSHOT 工件是临时的,可能会更改或被删除。要使用这些工件,您必须在 https://repository.apache.org/snapshots/ 添加 ASF 快照仓库。
groupId: org.apache.spark
artifactId: spark-core_2.12
version: 3.0.0-SNAPSHOT
使用 YourKit 分析 Spark 应用程序
以下是使用 YourKit Java Profiler 分析 Spark 应用程序的说明。
在 Spark EC2 镜像上
- 登录主节点后,从 YourKit 下载页面下载适用于 Linux 的 YourKit Java Profiler。此文件相当大(约 100 MB),且 YourKit 下载站点速度较慢,因此您可以考虑镜像此文件或将其包含在自定义 AMI 中。
- 将此文件解压到某个位置(在我们的例子中是
/root):unzip YourKit-JavaProfiler-2017.02-b66.zip - 使用 copy-dir 将解压后的 YourKit 文件复制到每个节点:
~/spark-ec2/copy-dir /root/YourKit-JavaProfiler-2017.02 - 通过编辑
~/spark/conf/spark-env.sh并添加以下行,配置 Spark JVM 以使用 YourKit 性能分析代理SPARK_DAEMON_JAVA_OPTS+=" -agentpath:/root/YourKit-JavaProfiler-2017.02/bin/linux-x86-64/libyjpagent.so=sampling" export SPARK_DAEMON_JAVA_OPTS SPARK_EXECUTOR_OPTS+=" -agentpath:/root/YourKit-JavaProfiler-2017.02/bin/linux-x86-64/libyjpagent.so=sampling" export SPARK_EXECUTOR_OPTS - 将更新后的配置复制到每个节点:
~/spark-ec2/copy-dir ~/spark/conf/spark-env.sh - 重启您的 Spark 集群:
~/spark/bin/stop-all.sh和~/spark/bin/start-all.sh - 默认情况下,YourKit 性能分析代理使用端口
10001-10010。要将 YourKit 桌面应用程序连接到远程性能分析代理,您必须在集群的 EC2 安全组中打开这些端口。为此,请登录 AWS 管理控制台。转到 EC2 部分,从页面左侧的Network & Security部分选择Security Groups。找到与您的集群对应的安全组;如果您启动了一个名为test_cluster的集群,那么您将需要修改test_cluster-slaves和test_cluster-master安全组的设置。对于每个组,从列表中选择它,点击Inbound选项卡,然后创建一个新的Custom TCP Rule,打开端口范围10001-10010。最后,点击Apply Rule Changes。请确保对两个安全组都执行此操作。注意:默认情况下,spark-ec2会重用安全组:如果您停止此集群并启动另一个同名集群,您的安全组设置将被重用。 - 在您的桌面上启动 YourKit 性能分析器。
- 从欢迎屏幕中选择“Connect to remote application…”,然后输入您的 Spark 主节点或工作节点的地址,例如
ec2--.compute-1.amazonaws.com - YourKit 现在应该已连接到远程性能分析代理。可能需要一些时间才能显示性能分析信息。
请参阅完整的 YourKit 文档以获取性能分析代理的完整 启动选项 列表。
在 Spark 单元测试中
通过 SBT 运行 Spark 测试时,将 javaOptions in Test += "-agentpath:/path/to/yjp" 添加到 SparkBuild.scala 中,以启用 YourKit 性能分析代理来启动测试。
性能分析代理的平台特定路径列在 YourKit 文档中。
生成式工具的使用
通常,ASF 允许使用生成式 AI 工具共同创作的贡献。但是,当您提交包含生成内容的补丁时,有几个注意事项。
首先,您需要披露此类工具的使用情况。此外,您有责任确保相关工具的条款和条件与开源项目中的使用兼容,并且包含生成的内容不会带来版权侵犯的风险。
有关详细信息和进展,请参阅 ASF 生成式工具指南。
最新消息
- Spark 3.5.6 发布 (2025 年 5 月 29 日)
- Spark 4.0.0 发布 (2025 年 5 月 23 日)
- Spark 3.5.5 发布 (2025 年 2 月 27 日)
- Spark 3.5.4 发布 (2024 年 12 月 20 日)
