Spark 发布 0.8.0
Apache Spark 0.8.0 是一个重要版本,包含许多新功能和可用性改进。这也是我们在 Apache 孵化器中的第一个版本。它是迄今为止最大的 Spark 版本,由 67 位开发者和 24 家公司贡献。
您可以下载 Spark 0.8.0 的源代码包(4 MB tar.gz),或用于 Hadoop 1 / CDH3 或 CDH4 的预构建包(125 MB tar.gz)。发布签名和校验和可在官方 Apache 下载站点获取。
监控 UI 和指标
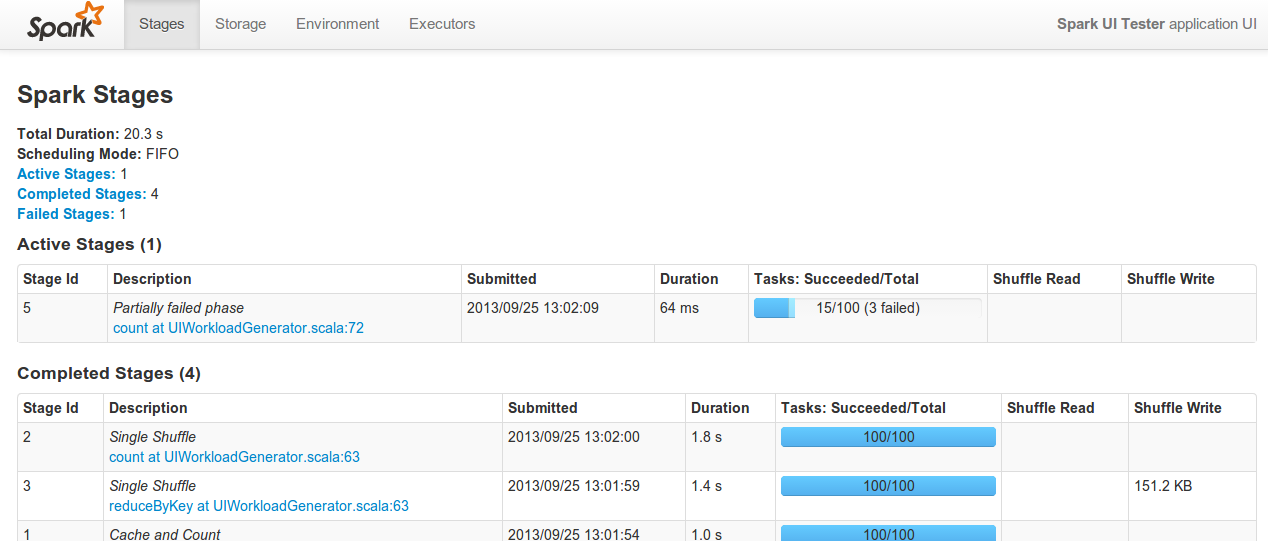
Spark 现在在 Web UI 中显示各种监控数据(默认在驱动节点上的 4040 端口)。新的作业仪表板包含有关正在运行、已成功和已失败作业的信息,包括涵盖任务运行时、混洗数据和垃圾回收的百分位数统计数据。现有的存储仪表板已得到扩展,并添加了额外的页面以显示每个执行器的总存储和任务信息。最后,一个新的指标库通过各种 API(包括 JMX 和 Ganglia)暴露 Spark 内部指标。
机器学习库
此版本引入了 MLlib,这是一个高质量的机器学习和优化算法标准库,用于 Spark。MLlib 是与 加州大学伯克利分校 MLbase 项目合作开发的。当前库包含七种算法,包括支持向量机 (SVM)、逻辑回归、线性回归的几种正则化变体、一种聚类算法 (KMeans) 和交替最小二乘协同过滤。
Python 改进
Python API 已扩展,增加了许多以前缺失的功能。这包括支持不同的存储级别、采样以及各种缺失的 RDD 运算符。我们还增加了在 IPython 中运行 Spark 的支持(包括 IPython Notebook),以及在 Windows 上运行 PySpark 的支持。
Hadoop YARN 支持
Spark 0.8 极大地改进了在 YARN 集群上运行独立 Spark 作业的支持。YARN 支持不再是实验性的,而是现在 Spark 主线的一部分。还增加了对在安全 YARN 集群上运行的支持。
改进的作业调度器
Spark 的内部作业调度器已经过重构和扩展,以包含更复杂的调度策略。特别是,现在公平调度器的实现允许多个用户共享一个 Spark 实例,这有助于运行较短作业的用户即使在较长作业并行运行时也能获得良好的性能。对拓扑感知调度的支持已得到扩展,包括考虑机架局部性和支持在单台机器上运行多个执行器的能力。
更简单的部署和链接
用户程序现在可以链接到 Spark,无论他们需要哪个 Hadoop 版本,而无需专门为该 Hadoop 版本发布一个 spark-core 版本。有关如何链接不同 Hadoop 版本的说明,请参阅此处。
扩展的 EC2 功能
Spark 的 EC2 脚本现在支持在任何可用区启动。还增加了对使用较新“HVM”架构的 EC2 实例类型的支持。这包括集群计算 (cc1/cc2) 系列实例类型。我们还增加了与 Spark 一起运行较新 HDFS 版本的支持。最后,除了启动最新版本外,我们还增加了启动包含 Spark 维护版本的集群的能力。
改进的文档
此版本增加了关于集群硬件配置以及与常见 Hadoop 发行版互操作的文档。文档还包括 MLlib 机器学习功能和新的集群监控功能。现有文档已更新,以反映 Spark 构建和部署方面的变化。
其他改进
- RDD 现在可以使用
unpersist手动从内存中删除。 - RDD 类包括以下新操作:
takeOrdered,zipPartitions,top。 - 已添加
JobLogger类,用于生成 Spark 工作负载的可存档日志。 RDD.coalesce函数现在考虑局部性。RDD.pipe函数已扩展,支持将环境变量传递给子进程。- Hadoop
save函数现在支持可选的压缩编解码器。 - 您现在可以创建仅依赖 Java 运行时的 Spark 二进制发行版,以便在集群上更轻松地部署。
- 示例构建已与核心构建隔离,大大减少了依赖冲突的可能性。
- Spark Streaming Twitter API 已更新为使用 OAuth 认证,而不是 Spark 0.7.0 中已弃用的用户名/密码认证。
- 新增了几个示例作业,包括 Java、Scala 和 Python 中的 PageRank 实现,访问 HBase 和 Cassandra 的示例,以及 MLlib 示例。
- 对在 Mesos 上运行的支持已得到改进——现在您可以将 Spark assembly JAR 作为 Mesos 作业的一部分进行部署,而无需在每台机器上预先安装 Spark。默认的 Mesos 版本也已更新到 0.13。
- 此版本包括对 PySpark 和作业调度器的各种优化。
兼容性
- 此版本将 Spark 的包名更改为 'org.apache.spark',因此从 Spark 0.7 升级的用户需要相应地调整其导入。此外,我们将
RDD类移动到 org.apache.spark.rdd 包(它以前在顶级包中)。通过 Maven 发布 Spark 工件也已更改为新的包名。 - 在 Java API 中,Scala 的
Option类的使用已替换为 Guava 库中的Optional。 - 现在可以通过指定对
hadoop-client的依赖来链接 Spark,以支持任意 Hadoop 版本,而无需针对您的 Hadoop 版本重建spark-core。详情请参阅此处的文档。 - 如果您正在构建 Spark,现在需要运行
sbt/sbt assembly而不是package。
致谢
Spark 0.8.0 是迄今为止最大贡献者团队的成果。以下开发者为此次发布做出了贡献:
- Andrew Ash – 文档、代码清理和日志改进
- Mikhail Bautin – 错误修复
- Konstantin Boudnik – Maven 构建、错误修复和文档
- Ian Buss – sbt 配置改进
- Evan Chan – API 改进、错误修复和文档
- Lian Cheng – 错误修复
- Tathagata Das – 流式接收器性能改进和流式错误修复
- Aaron Davidson – Python 改进、错误修复和单元测试
- Giovanni Delussu – 合并 RDD 功能
- Joseph E. Gonzalez – zipPartitions 改进
- Karen Feng – Web UI 的多项改进
- Andy Feng – HDFS 指标
- Ali Ghodsi – 配置改进和局部性感知合并
- Christoph Grothaus – 错误修复
- Thomas Graves – 安全 YARN 集群支持和各种 YARN 相关改进
- Stephen Haberman – 错误修复、文档和代码清理
- Mark Hamstra – 错误修复和 Maven 构建
- Benjamin Hindman – Mesos 兼容性和文档
- Liang-Chi Hsieh – 构建和 YARN 模式下的错误修复
- Shane Huang – shuffle 改进,错误修复
- Ethan Jewett – Spark/HBase 示例
- Holden Karau – 错误修复和 EC2 改进
- Kody Koeniger – JDBV RDD 实现
- Andy Konwinski – 文档
- Jey Kottalam – PySpark 优化,Hadoop 无关构建(负责人)和错误修复
- Andrey Kouznetsov – 错误修复
- S. Kumar – Spark Streaming 示例
- Ryan LeCompte – topK 方法优化和序列化改进
- Gavin Li – 压缩编解码器和管道支持
- Harold Lim – 公平调度器
- Dmitriy Lyubimov – 错误修复
- Chris Mattmann – Apache 导师
- David McCauley – JSON API 改进
- Sean McNamara – 添加了
takeOrdered函数,错误修复和构建修复 - Mridul Muralidharan – YARN 集成(负责人)和调度器改进
- Marc Mercer – UI json 输出的改进
- Christopher Nguyen – 错误修复
- Erik van Oosten – 示例修复
- Kay Ousterhout – 调度器回归修复和错误修复
- Xinghao Pan – MLLib 贡献
- Hiral Patel – 错误修复
- James Phillpotts – 更新了 Spark streaming 的 Twitter API
- Nick Pentreath – Scala PageRank 示例、Bagel 改进和几个 Java 示例
- Alexander Pivovarov – 日志改进和 Maven 构建
- Mike Potts – 配置改进
- Rohit Rai – Spark/Cassandra 示例
- Imran Rashid – 错误修复和 UI 改进
- Charles Reiss – 错误修复、代码清理、性能改进
- Josh Rosen – Python API 改进、Java API 改进、EC2 脚本和错误修复
- Henry Saputra – Apache 导师
- Jerry Shao – 错误修复、指标系统
- Prashant Sharma – 文档
- Mingfei Shi – joblogger 和错误修复
- Andre Schumacher – 几个 PySpark 功能
- Ginger Smith – MLLib 贡献
- Evan Sparks – 对 MLLib 的贡献
- Ram Sriharsha – 错误修复和 RDD 删除功能
- Ameet Talwalkar – MLlib 贡献
- Roman Tkalenko – 代码重构和清理
- Chu Tong – Java PageRank 算法和 bash 脚本中的错误修复
- Shivaram Venkataraman – 错误修复、对 MLLib 的贡献、netty shuffle 修复和 Java API 添加
- Patrick Wendell – 发布经理、错误修复、文档、指标系统和 Web UI
- Andrew Xia – 公平调度器(负责人)、指标系统和 UI 改进
- Reynold Xin – shuffle 改进、错误修复、代码重构、可用性改进、MLLib 贡献
- Matei Zaharia – MLLib 贡献、文档、示例、UI 改进、PySpark 改进和错误修复
- Wu Zeming – 调度器中的错误修复
- Bill Zhao – 日志消息改进
感谢所有贡献者!我们特别感谢 Patrick Wendell 担任此版本的发布经理。
最新新闻
- Spark 3.5.6 发布 (2025 年 5 月 29 日)
- Spark 4.0.0 发布 (2025 年 5 月 23 日)
- Spark 3.5.5 发布 (2025 年 2 月 27 日)
- Spark 3.5.4 发布 (2024 年 12 月 20 日)
