MLlib 是 Apache Spark 的可扩展机器学习库。
易用性
可在 Java、Scala、Python 和 R 中使用。
MLlib 符合 Spark 的 API,并与 Python 中的 NumPy(从 Spark 0.9 开始)和 R 库(从 Spark 1.5 开始)互操作。您可以使用任何 Hadoop 数据源(例如 HDFS、HBase 或本地文件),从而轻松地将其插入到 Hadoop 工作流中。
data = spark.read.format("libsvm")\
.load("hdfs://...")
model = KMeans(k=10).fit(data)
.load("hdfs://...")
model = KMeans(k=10).fit(data)
在 Python 中调用 MLlib
性能
高质量算法,比 MapReduce 快 100 倍。
Spark 在迭代计算方面表现出色,使 MLlib 能够快速运行。同时,我们关注算法性能:MLlib 包含利用迭代的高质量算法,并且可以比 MapReduce 中有时使用的一次近似法产生更好的结果。
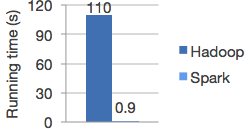
Hadoop 和 Spark 中的逻辑回归
随处运行
Spark 可在 Hadoop、Apache Mesos、Kubernetes、独立模式或云端运行,并支持各种数据源。
您可以使用 Spark 的独立集群模式,在 EC2、Hadoop YARN、Mesos 或 Kubernetes 上运行 Spark。可访问 HDFS、Apache Cassandra、Apache HBase、Apache Hive 以及数百种其他数据源中的数据。

算法
MLlib 包含许多算法和实用工具。
ML 算法包括
- 分类:逻辑回归、朴素贝叶斯等
- 回归:广义线性回归、生存回归等
- 决策树、随机森林和梯度提升树
- 推荐:交替最小二乘法 (ALS)
- 聚类:K-均值、高斯混合模型 (GMM) 等
- 主题模型:隐含狄利克雷分配 (LDA)
- 频繁项集、关联规则和序列模式挖掘
ML 工作流实用工具包括
- 特征转换:标准化、归一化、哈希等
- ML Pipeline 构建
- 模型评估和超参数调优
- ML 持久化:保存和加载模型及 Pipeline
其他实用工具包括
- 分布式线性代数:SVD、PCA 等
- 统计:摘要统计、假设检验等
有关使用示例,请参阅MLlib 指南。
社区
MLlib 是作为 Apache Spark 项目的一部分进行开发的。因此,它会随每个 Spark 版本进行测试和更新。
如果您对该库有疑问,请在Spark 邮件列表上提问。
MLlib 仍然是一个快速发展的项目,欢迎贡献。如果您想为 MLlib 提交算法,请阅读如何为 Spark 贡献并向我们发送补丁!
最新消息
- Spark 3.5.6 发布 (2025 年 5 月 29 日)
- Spark 4.0.0 发布 (2025 年 5 月 23 日)
- Spark 3.5.5 发布 (2025 年 2 月 27 日)
- Spark 3.5.4 发布 (2024 年 12 月 20 日)
