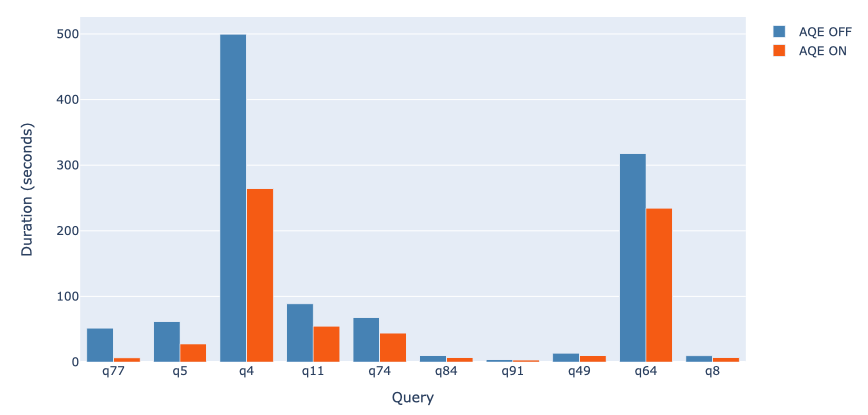
简单。
快速。
可扩展。
统一。
快速。
可扩展。
统一。
主要特点
批处理/流式数据
使用您喜欢的语言(Python、SQL、Scala、Java 或 R)统一处理您的批处理和实时流数据。
SQL 分析
执行快速、分布式的 ANSI SQL 查询,用于仪表板和临时报告。运行速度比大多数数据仓库更快。
大规模数据科学
对 PB 级数据执行探索性数据分析 (EDA),而无需进行降采样。
机器学习
在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到具有容错能力的数千台机器集群。