调试 PySpark¶
PySpark 使用 Spark 作为引擎。 PySpark 使用 Py4J 来利用 Spark 提交和计算作业。
在驱动端,PySpark 使用 Py4J 与 JVM 上的驱动程序通信。当 pyspark.sql.SparkSession 或 pyspark.SparkContext 被创建和初始化时,PySpark 启动一个 JVM 进行通信。
在执行器端,Python worker 执行并处理 Python 本地函数或数据。如果 PySpark 应用程序不需要 Python worker 和 JVM 之间的交互,则不会启动它们。只有在必须处理 Python 本地函数或数据时才会被延迟启动,例如,当您执行 pandas UDF 或 PySpark RDD API 时。
本页面侧重于调试 PySpark 的 Python 端,包括驱动端和执行器端,而不是侧重于使用 JVM 进行调试。分析和调试 JVM 在 有用的开发者工具 中进行了描述。
请注意,
如果您在本地运行,您可以直接使用 IDE 调试驱动端,而无需远程调试功能。使用 IDE 设置 PySpark 在 这里 进行了记录。
有很多其他方法可以调试 PySpark 应用程序。例如,您可以使用开源的 远程调试器 而不是使用此处记录的 PyCharm Professional 进行远程调试。
远程调试 (PyCharm Professional)¶
本节描述了在单台机器上对驱动端和执行器端进行远程调试,以便轻松演示。在执行器端调试 PySpark 的方法与在驱动端调试不同。因此,将分别演示它们。为了在其他机器上调试 PySpark 应用程序,请参阅 PyCharm 特有的完整说明,记录在 这里。
首先,从 Run 菜单中选择 Edit Configuration… 。这将打开 Run/Debug Configurations dialog。您必须单击工具栏上的 + 配置,然后从可用配置列表中选择 Python Debug Server。输入此新配置的名称,例如,MyRemoteDebugger,并指定端口号,例如 12345。
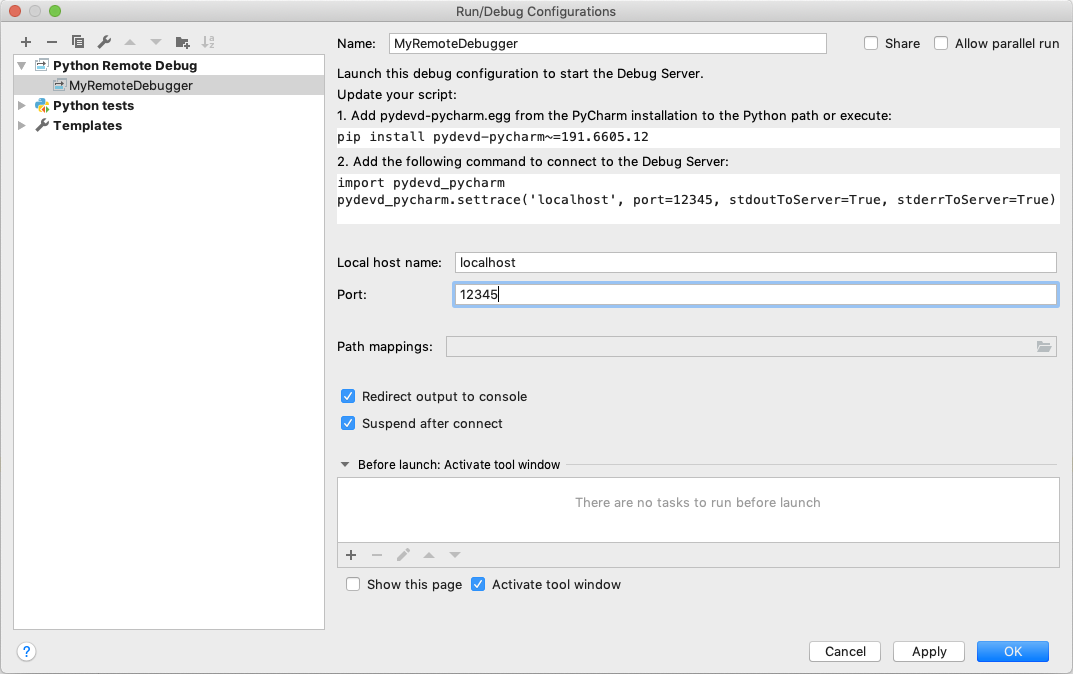
pydevd-pycharm 包。在上一个对话框中,它显示了安装命令。pip install pydevd-pycharm~=<version of PyCharm on the local machine>
驱动端¶
要在驱动端进行调试,您的应用程序应该能够连接到调试服务器。将带有 pydevd_pycharm.settrace 的代码复制并粘贴到您的 PySpark 脚本的顶部。假设脚本名称是 app.py
echo "#======================Copy and paste from the previous dialog===========================
import pydevd_pycharm
pydevd_pycharm.settrace('localhost', port=12345, stdoutToServer=True, stderrToServer=True)
#========================================================================================
# Your PySpark application codes:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).show()" > app.py
开始使用您的 MyRemoteDebugger 进行调试。

spark-submit app.py
执行器端¶
要在执行器端进行调试,请在您当前的工作目录中准备一个 Python 文件,如下所示。
echo "from pyspark import daemon, worker
def remote_debug_wrapped(*args, **kwargs):
#======================Copy and paste from the previous dialog===========================
import pydevd_pycharm
pydevd_pycharm.settrace('localhost', port=12345, stdoutToServer=True, stderrToServer=True)
#========================================================================================
worker.main(*args, **kwargs)
daemon.worker_main = remote_debug_wrapped
if __name__ == '__main__':
daemon.manager()" > remote_debug.py
您将通过使用 spark.python.daemon.module 配置将此文件用作 PySpark 应用程序中的 Python worker。使用以下配置运行 pyspark shell
pyspark --conf spark.python.daemon.module=remote_debug
现在您已准备好进行远程调试。开始使用您的 MyRemoteDebugger 进行调试。
spark.range(10).repartition(1).rdd.map(lambda x: x).collect()
检查资源使用情况 (top 和 ps)¶
可以通过典型方式(例如 top 和 ps 命令)检查驱动程序和执行程序上的 Python 进程。
驱动端¶
在驱动程序端,您可以轻松地从 PySpark shell 中获取进程 ID,如下所示,以了解进程 ID 和资源。
>>> import os; os.getpid()
18482
ps -fe 18482
UID PID PPID C STIME TTY TIME CMD
000 18482 12345 0 0:00PM ttys001 0:00.00 /.../python
执行器端¶
要在执行器端进行检查,您可以简单地 grep 它们以找出进程 ID 和相关资源,因为 Python worker 是从 pyspark.daemon 派生的。
ps -fe | grep pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
000 12345 1 0 0:00PM ttys000 0:00.00 /.../python -m pyspark.daemon
...
分析内存使用情况(Memory Profiler)¶
memory_profiler 是一个分析器,允许您逐行检查内存使用情况。
驱动端¶
除非您在另一台机器上运行驱动程序(例如,YARN 集群模式),否则可以使用此有用的工具轻松调试驱动程序端的内存使用情况。假设您的 PySpark 脚本名称是 profile_memory.py。您可以按如下方式对其进行分析。
echo "from pyspark.sql import SparkSession
#===Your function should be decorated with @profile===
from memory_profiler import profile
@profile
#=====================================================
def my_func():
session = SparkSession.builder.getOrCreate()
df = session.range(10000)
return df.collect()
if __name__ == '__main__':
my_func()" > profile_memory.py
python -m memory_profiler profile_memory.py
Filename: profile_memory.py
Line # Mem usage Increment Line Contents
================================================
...
6 def my_func():
7 51.5 MiB 0.6 MiB session = SparkSession.builder.getOrCreate()
8 51.5 MiB 0.0 MiB df = session.range(10000)
9 54.4 MiB 2.8 MiB return df.collect()
Python/Pandas UDF¶
PySpark 为 Python/Pandas UDF 提供了远程 memory_profiler,可以通过将 spark.python.profile.memory 配置设置为 true 来启用。这可以在具有行号的编辑器(如 Jupyter 笔记本)中使用。Jupyter 笔记本上的一个示例如下所示。
pyspark --conf spark.python.profile.memory=true
from pyspark.sql.functions import pandas_udf
df = spark.range(10)
@pandas_udf("long")
def add1(x):
return x + 1
added = df.select(add1("id"))
added.show()
sc.show_profiles()
结果配置文件如下所示。
============================================================
Profile of UDF<id=2>
============================================================
Filename: ...
Line # Mem usage Increment Occurrences Line Contents
=============================================================
4 974.0 MiB 974.0 MiB 10 @pandas_udf("long")
5 def add1(x):
6 974.4 MiB 0.4 MiB 10 return x + 1
可以在查询计划中看到 UDF ID,例如,如下所示的 ArrowEvalPython 中的 add1(...)#2L。
added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#11L AS add1(id)#3L]
+- ArrowEvalPython [add1(id#0L)#2L], [pythonUDF0#11L], 200
+- *(1) Range (0, 10, step=1, splits=16)
注册的 UDF 或具有迭代器作为输入/输出的 UDF 不支持此功能。
识别热循环(Python Profilers)¶
Python Profilers 是 Python 本身中非常有用的内置功能。这些功能提供了 Python 程序的确定性分析,并提供了许多有用的统计信息。本节介绍如何在驱动程序和执行程序端使用它,以便识别昂贵或热代码路径。
驱动端¶
要在驱动程序端使用此功能,您可以像对常规 Python 程序一样使用它,因为驱动程序端的 PySpark 是一个常规 Python 进程,除非您在另一台计算机上运行驱动程序(例如,YARN 集群模式)。
echo "from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).show()" > app.py
python -m cProfile app.py
...
129215 function calls (125446 primitive calls) in 5.926 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1198/405 0.001 0.000 0.083 0.000 <frozen importlib._bootstrap>:1009(_handle_fromlist)
561 0.001 0.000 0.001 0.000 <frozen importlib._bootstrap>:103(release)
276 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
276 0.000 0.000 0.002 0.000 <frozen importlib._bootstrap>:147(__enter__)
...
执行器端¶
要在执行器端使用此功能,PySpark 为执行器端提供了远程 Python Profilers,可以通过将 spark.python.profile 配置设置为 true 来启用。
pyspark --conf spark.python.profile=true
>>> rdd = sc.parallelize(range(100)).map(str)
>>> rdd.count()
100
>>> sc.show_profiles()
============================================================
Profile of RDD<id=1>
============================================================
728 function calls (692 primitive calls) in 0.004 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
12 0.001 0.000 0.001 0.000 serializers.py:210(load_stream)
12 0.000 0.000 0.000 0.000 {built-in method _pickle.dumps}
12 0.000 0.000 0.001 0.000 serializers.py:252(dump_stream)
12 0.000 0.000 0.001 0.000 context.py:506(f)
...
Python/Pandas UDF¶
要在 Python/Pandas UDF 上使用此功能,PySpark 为 Python/Pandas UDF 提供了远程 Python Profilers,可以通过将 spark.python.profile 配置设置为 true 来启用。
pyspark --conf spark.python.profile=true
>>> from pyspark.sql.functions import pandas_udf
>>> df = spark.range(10)
>>> @pandas_udf("long")
... def add1(x):
... return x + 1
...
>>> added = df.select(add1("id"))
>>> added.show()
+--------+
|add1(id)|
+--------+
...
+--------+
>>> sc.show_profiles()
============================================================
Profile of UDF<id=2>
============================================================
2300 function calls (2270 primitive calls) in 0.006 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
10 0.001 0.000 0.005 0.001 series.py:5515(_arith_method)
10 0.001 0.000 0.001 0.000 _ufunc_config.py:425(__init__)
10 0.000 0.000 0.000 0.000 {built-in method _operator.add}
10 0.000 0.000 0.002 0.000 series.py:315(__init__)
...
可以在查询计划中看到 UDF ID,例如,下面的 ArrowEvalPython 中的 add1(...)#2L。
>>> added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#11L AS add1(id)#3L]
+- ArrowEvalPython [add1(id#0L)#2L], [pythonUDF0#11L], 200
+- *(1) Range (0, 10, step=1, splits=16)
注册的 UDF 不支持此功能。
常见异常/错误¶
PySpark SQL¶
AnalysisException
当无法分析 SQL 查询计划时,会引发 AnalysisException。
示例
>>> df = spark.range(1)
>>> df['bad_key']
Traceback (most recent call last):
...
pyspark.errors.exceptions.AnalysisException: Cannot resolve column name "bad_key" among (id)
解决方案
>>> df['id']
Column<'id'>
ParseException
当无法解析 SQL 命令时,会引发 ParseException。
示例
>>> spark.sql("select * 1")
Traceback (most recent call last):
...
pyspark.errors.exceptions.ParseException:
[PARSE_SYNTAX_ERROR] Syntax error at or near '1': extra input '1'.(line 1, pos 9)
== SQL ==
select * 1
---------^^^
解决方案
>>> spark.sql("select *")
DataFrame[]
IllegalArgumentException
当传递非法或不适当的参数时,会引发 IllegalArgumentException。
示例
>>> spark.range(1).sample(-1.0)
Traceback (most recent call last):
...
pyspark.errors.exceptions.IllegalArgumentException: requirement failed: Sampling fraction (-1.0) must be on interval [0, 1] without replacement
解决方案
>>> spark.range(1).sample(1.0)
DataFrame[id: bigint]
PythonException
从 Python worker 抛出 PythonException。
您可以查看从 Python worker 抛出的异常类型及其堆栈跟踪,如下面的 TypeError。
示例
>>> import pyspark.sql.functions as sf
>>> from pyspark.sql.functions import udf
>>> def f(x):
... return sf.abs(x)
...
>>> spark.range(-1, 1).withColumn("abs", udf(f)("id")).collect()
22/04/12 14:52:31 ERROR Executor: Exception in task 7.0 in stage 37.0 (TID 232)
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
...
TypeError: Invalid argument, not a string or column: -1 of type <class 'int'>. For column literals, use 'lit', 'array', 'struct' or 'create_map' function.
解决方案
>>> def f(x):
... return abs(x)
...
>>> spark.range(-1, 1).withColumn("abs", udf(f)("id")).collect()
[Row(id=-1, abs='1'), Row(id=0, abs='0')]
StreamingQueryException
当 StreamingQuery 失败时,会引发 StreamingQueryException。通常,它从 Python worker 抛出,并将其包装为 PythonException。
示例
>>> sdf = spark.readStream.format("text").load("python/test_support/sql/streaming")
>>> from pyspark.sql.functions import col, udf
>>> bad_udf = udf(lambda x: 1 / 0)
>>> (sdf.select(bad_udf(col("value"))).writeStream.format("memory").queryName("q1").start()).processAllAvailable()
Traceback (most recent call last):
...
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "<stdin>", line 1, in <lambda>
ZeroDivisionError: division by zero
...
pyspark.errors.exceptions.StreamingQueryException: [STREAM_FAILED] Query [id = 74eb53a8-89bd-49b0-9313-14d29eed03aa, runId = 9f2d5cf6-a373-478d-b718-2c2b6d8a0f24] terminated with exception: Job aborted
解决方案
修复 StreamingQuery 并重新执行工作流程。
SparkUpgradeException
由于 Spark 升级,抛出 SparkUpgradeException。
示例
>>> from pyspark.sql.functions import to_date, unix_timestamp, from_unixtime
>>> df = spark.createDataFrame([("2014-31-12",)], ["date_str"])
>>> df2 = df.select("date_str", to_date(from_unixtime(unix_timestamp("date_str", "yyyy-dd-aa"))))
>>> df2.collect()
Traceback (most recent call last):
...
pyspark.sql.utils.SparkUpgradeException: You may get a different result due to the upgrading to Spark >= 3.0: Fail to recognize 'yyyy-dd-aa' pattern in the DateTimeFormatter. 1) You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0. 2) You can form a valid datetime pattern with the guide from https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html
解决方案
>>> spark.conf.set("spark.sql.legacy.timeParserPolicy", "LEGACY")
>>> df2 = df.select("date_str", to_date(from_unixtime(unix_timestamp("date_str", "yyyy-dd-aa"))))
>>> df2.collect()
[Row(date_str='2014-31-12', to_date(from_unixtime(unix_timestamp(date_str, yyyy-dd-aa), yyyy-MM-dd HH:mm:ss))=None)]
Spark 上的 pandas API¶
在 Spark 上的 pandas API 中存在特定的常见异常/错误。
ValueError:无法合并序列或数据帧,因为它来自不同的数据帧
如果 compute.ops_on_diff_frames 被禁用(默认禁用),则涉及多个 series 或 dataframe 的操作会引发 ValueError。 由于底层 Spark frames 的连接,此类操作可能会很昂贵。 因此,用户应了解成本,并仅在必要时启用该标志。
异常
>>> ps.Series([1, 2]) + ps.Series([3, 4])
Traceback (most recent call last):
...
ValueError: Cannot combine the series or dataframe because it comes from a different dataframe. In order to allow this operation, enable 'compute.ops_on_diff_frames' option.
解决方案
>>> with ps.option_context('compute.ops_on_diff_frames', True):
... ps.Series([1, 2]) + ps.Series([3, 4])
...
0 4
1 6
dtype: int64
RuntimeError:pandas_udf 的结果向量长度不符合要求
异常
>>> def f(x) -> ps.Series[np.int32]:
... return x[:-1]
...
>>> ps.DataFrame({"x":[1, 2], "y":[3, 4]}).transform(f)
22/04/12 13:46:39 ERROR Executor: Exception in task 2.0 in stage 16.0 (TID 88)
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
...
RuntimeError: Result vector from pandas_udf was not the required length: expected 1, got 0
解决方案
>>> def f(x) -> ps.Series[np.int32]:
... return x
...
>>> ps.DataFrame({"x":[1, 2], "y":[3, 4]}).transform(f)
x y
0 1 3
1 2 4
Py4j¶
Py4JJavaError
当 Java 客户端代码中发生异常时,会引发 Py4JJavaError。 您可以看到 Java 端抛出的异常类型及其堆栈跟踪,如下面的 java.lang.NullPointerException。
示例
>>> spark.sparkContext._jvm.java.lang.String(None)
Traceback (most recent call last):
...
py4j.protocol.Py4JJavaError: An error occurred while calling None.java.lang.String.
: java.lang.NullPointerException
..
解决方案
>>> spark.sparkContext._jvm.java.lang.String("x")
'x'
Py4JError
当发生任何其他错误时会引发 Py4JError,例如当 Python 客户端程序尝试访问 Java 端不再存在的对象时。
示例
>>> from pyspark.ml.linalg import Vectors
>>> from pyspark.ml.regression import LinearRegression
>>> df = spark.createDataFrame(
... [(1.0, 2.0, Vectors.dense(1.0)), (0.0, 2.0, Vectors.sparse(1, [], []))],
... ["label", "weight", "features"],
... )
>>> lr = LinearRegression(
... maxIter=1, regParam=0.0, solver="normal", weightCol="weight", fitIntercept=False
... )
>>> model = lr.fit(df)
>>> model
LinearRegressionModel: uid=LinearRegression_eb7bc1d4bf25, numFeatures=1
>>> model.__del__()
>>> model
Traceback (most recent call last):
...
py4j.protocol.Py4JError: An error occurred while calling o531.toString. Trace:
py4j.Py4JException: Target Object ID does not exist for this gateway :o531
...
解决方案
访问 Java 端存在的对象。
Py4JNetworkError
当网络传输期间出现问题时(例如,连接丢失),会引发 Py4JNetworkError。 在这种情况下,我们应该调试网络并重建连接。
堆栈跟踪¶
有一些 Spark 配置可以控制堆栈跟踪
spark.sql.execution.pyspark.udf.simplifiedTraceback.enabled默认设置为 true,以简化 Python UDF 中的回溯。spark.sql.pyspark.jvmStacktrace.enabled默认设置为 false,以隐藏 JVM 堆栈跟踪并仅显示对 Python 友好的异常。
上述 Spark 配置独立于日志级别设置。 通过 pyspark.SparkContext.setLogLevel() 控制日志级别。