Web UI
Apache Spark 提供了一套 Web 用户界面(UI),可用于监控 Spark 集群的状态和资源消耗。
目录
- 作业 (Jobs) 标签页
- 阶段 (Stages) 标签页
- 存储 (Storage) 标签页
- 环境 (Environment) 标签页
- 执行器 (Executors) 标签页
- SQL 标签页
- 结构化流 (Structured Streaming) 标签页
- 流式处理 (Streaming (DStreams)) 标签页
- JDBC/ODBC 服务器标签页
作业 (Jobs) 标签页
作业 (Jobs) 标签页显示 Spark 应用程序中所有作业的摘要页面和每个作业的详情页面。摘要页面显示高级信息,例如所有作业的状态、持续时间、进度以及整体事件时间线。当您点击摘要页面上的某个作业时,您将看到该作业的详情页面。详情页面进一步显示了事件时间线、DAG 可视化以及作业的所有阶段。
本节显示的信息包括:
- 用户:当前 Spark 用户
- 启动时间:Spark 应用程序的启动时间
- 总运行时间:Spark 应用程序启动以来的时间
- 调度模式:参见 作业调度
- 各状态作业数量:活动中、已完成、失败

- 事件时间线:按时间顺序显示与执行器(添加、删除)和作业相关的事件

- 按状态分组的作业详情:显示作业的详细信息,包括作业 ID、描述(包含指向作业详情页面的链接)、提交时间、持续时间、阶段摘要和任务进度条

当您点击某个特定的作业时,您可以看到该作业的详细信息。
作业详情
此页面显示由其作业 ID 标识的特定作业的详细信息。
- 作业状态:(运行中、成功、失败)
- 各状态阶段数量(活动中、待处理、已完成、已跳过、失败)
- 关联 SQL 查询:指向此作业的 SQL 标签页的链接
- 事件时间线:按时间顺序显示与执行器(添加、删除)和作业阶段相关的事件

- DAG 可视化:此作业的有向无环图的图形表示,其中顶点代表 RDD 或 DataFrame,边代表要应用于 RDD 的操作。
sc.parallelize(1 to 100).toDF.count()的 DAG 可视化示例

- 阶段列表(按状态分组:活动中、待处理、已完成、已跳过、失败)
- 阶段 ID
- 阶段描述
- 提交时间戳
- 阶段持续时间
- 任务进度条
- 输入:此阶段从存储中读取的字节数
- 输出:此阶段写入存储的字节数
- Shuffle 读取:总共的 shuffle 字节和记录数,包括本地读取的数据和从远程执行器读取的数据
- Shuffle 写入:写入磁盘的字节和记录数,以便在未来的阶段中进行 shuffle 读取

阶段 (Stages) 标签页
阶段 (Stages) 标签页显示一个摘要页面,显示 Spark 应用程序中所有作业的所有阶段的当前状态。
页面开头是所有阶段按状态(活动中、待处理、已完成、已跳过、失败)计数的摘要


之后是按状态(活动中、待处理、已完成、已跳过、失败)划分的阶段详情。在活动阶段,可以通过“kill”链接终止该阶段。只有在失败阶段才会显示失败原因。点击描述即可访问任务详情。

阶段详情
阶段详情页面以总任务时间、本地性级别摘要、Shuffle 读取大小/记录数和关联作业 ID 等信息开头。

此阶段还有一个有向无环图(DAG)的可视化表示,其中顶点代表 RDD 或 DataFrame,边代表要应用的操作。在 DAG 可视化中,节点按操作范围分组,并标有操作范围名称(BatchScan、WholeStageCodegen、Exchange 等)。值得注意的是,整阶段代码生成操作也使用代码生成 ID 进行注释。对于属于 Spark DataFrame 或 SQL 执行的阶段,这允许将阶段执行详情交叉引用到 Web UI SQL 标签页中的相关详情,其中报告了 SQL 计划图和执行计划。

所有任务的摘要指标以表格和时间线形式表示。
- 任务反序列化时间
- 任务持续时间.
- GC 时间是 JVM 垃圾回收的总时间。
- 结果序列化时间是在执行器上序列化任务结果并将其发送回驱动程序之前所花费的时间。
- 获取结果时间是驱动程序从 worker 获取任务结果所花费的时间。
- 调度延迟是任务等待被调度执行的时间。
- 峰值执行内存是 shuffle、聚合和连接期间创建的内部数据结构所使用的最大内存。
- Shuffle 读取大小/记录数。总共的 shuffle 字节数,包括本地读取的数据和从远程执行器读取的数据。
- Shuffle 读取获取等待时间是任务在等待从远程机器读取 shuffle 数据时阻塞所花费的时间。
- Shuffle 远程读取是从远程执行器读取的总 shuffle 字节数。
- Shuffle 写入时间是任务写入 shuffle 数据所花费的时间。
- Shuffle 溢出(内存)是 shuffle 数据的反序列化形式在内存中的大小。
- Shuffle 溢出(磁盘)是数据序列化形式在磁盘上的大小。

按执行器聚合的指标显示按执行器聚合的相同信息。

累加器是一种共享变量。它提供了一个可变变量,可以在各种转换中进行更新。可以创建带名称和不带名称的累加器,但只显示带名称的累加器。

任务详情基本上包含与摘要部分相同的信息,但按任务细分。它还包括查看日志的链接,以及如果任务因任何原因失败时的任务尝试次数。如果存在命名累加器,可以在此处查看每个任务结束时的累加器值。

存储 (Storage) 标签页
存储 (Storage) 标签页显示应用程序中任何持久化的 RDD 和 DataFrame。摘要页面显示所有 RDD 的存储级别、大小和分区,详情页面显示 RDD 或 DataFrame 中所有分区的大小和使用的执行器。
scala> import org.apache.spark.storage.StorageLevel._
import org.apache.spark.storage.StorageLevel._
scala> val rdd = sc.range(0, 100, 1, 5).setName("rdd")
rdd: org.apache.spark.rdd.RDD[Long] = rdd MapPartitionsRDD[1] at range at <console>:27
scala> rdd.persist(MEMORY_ONLY_SER)
res0: rdd.type = rdd MapPartitionsRDD[1] at range at <console>:27
scala> rdd.count
res1: Long = 100
scala> val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df: org.apache.spark.sql.DataFrame = [count: int, name: string]
scala> df.persist(DISK_ONLY)
res2: df.type = [count: int, name: string]
scala> df.count
res3: Long = 3

运行上述示例后,我们可以在存储标签页中找到两个 RDD。提供了存储级别、分区数量和内存开销等基本信息。请注意,新持久化的 RDD 或 DataFrame 在具体化之前不会显示在标签页中。要监控特定的 RDD 或 DataFrame,请确保已触发了行动操作。

您可以点击 RDD 名称“rdd”以获取数据持久化的详细信息,例如集群上的数据分布。
环境 (Environment) 标签页
环境 (Environment) 标签页显示各种环境和配置变量的值,包括 JVM、Spark 和系统属性。

此环境页面包含五个部分。它是检查属性是否设置正确的好地方。第一部分“运行时信息”仅包含 运行时属性,例如 Java 和 Scala 的版本。第二部分“Spark 属性”列出了 应用程序属性,例如 “spark.app.name” 和 “spark.driver.memory”。

点击“Hadoop 属性”链接显示与 Hadoop 和 YARN 相关的属性。请注意,诸如 “spark.hadoop.*” 之类的属性不在此部分显示,而是在“Spark 属性”中显示。

“系统属性”显示有关 JVM 的更多详细信息。

最后一部分“类路径条目”列出了从不同源加载的类,这对于解决类冲突非常有用。
执行器 (Executors) 标签页
执行器 (Executors) 标签页显示为应用程序创建的执行器的摘要信息,包括内存和磁盘使用情况以及任务和 shuffle 信息。“存储内存”列显示用于缓存数据的内存量和预留量。

执行器 (Executors) 标签页不仅提供资源信息(每个执行器使用的内存量、磁盘和核心数),还提供性能信息(GC 时间和 shuffle 信息)。

点击执行器 0 的“stderr”链接,可以在其控制台中显示详细的 标准错误日志。

点击执行器 0 的“线程 Dump”链接,可以显示执行器 0 上 JVM 的线程 Dump,这对于性能分析非常有用。
SQL 标签页
如果应用程序执行 Spark SQL 查询,SQL 标签页会显示查询的持续时间、作业以及物理和逻辑计划等信息。这里我们包含一个基本示例来说明此标签页
scala> val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df: org.apache.spark.sql.DataFrame = [count: int, name: string]
scala> df.count
res0: Long = 3
scala> df.createGlobalTempView("df")
scala> spark.sql("select name,sum(count) from global_temp.df group by name").show
+----+----------+
|name|sum(count)|
+----+----------+
|andy| 3|
| bob| 2|
+----+----------+

现在,上述三个 DataFrame/SQL 运算符显示在列表中。如果我们点击最后一个查询的“show at <console>: 24”链接,我们将看到查询执行的 DAG 和详细信息。

查询详情页面显示查询执行时间、持续时间、关联作业列表和查询执行 DAG 等信息。第一个块“WholeStageCodegen (1)”将多个运算符(“LocalTableScan”和“HashAggregate”)编译成一个 Java 函数以提高性能,并且该块中列出了行数和溢出大小等指标。块名称中的注释“(1)”是代码生成 ID。第二个块“Exchange”显示 shuffle 交换的指标,包括写入的 shuffle 记录数、总数据大小等。

点击底部的“详细信息”链接,将显示逻辑计划和物理计划,它们说明了 Spark 如何解析、分析、优化和执行查询。物理计划中经过整阶段代码生成优化步骤,会以星号和代码生成 ID 为前缀,例如:“*(1) LocalTableScan”
SQL 指标
SQL 运算符的指标显示在物理运算符块中。SQL 指标在深入了解每个运算符的执行详情时会很有用。例如,“输出行数”可以回答 Filter 运算符之后输出了多少行,“Exchange”运算符中的“shuffle 写入总字节数”显示了 shuffle 写入的字节数。
以下是 SQL 指标列表
| SQL 指标 | 含义 | 运算符 |
|---|---|---|
输出行数 | 运算符的输出行数 | 聚合运算符、连接运算符、采样、范围、扫描运算符、过滤等。 |
数据大小 | 运算符的广播/shuffle/收集数据的大小 | BroadcastExchange, ShuffleExchange, Subquery |
收集时间 | 收集数据所花费的时间 | BroadcastExchange, Subquery |
扫描时间 | 扫描数据所花费的时间 | ColumnarBatchScan, FileSourceScan |
元数据时间 | 获取分区数量、文件数量等元数据所花费的时间 | FileSourceScan |
shuffle 写入字节数 | 写入的字节数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
shuffle 写入记录数 | 写入的记录数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
shuffle 写入时间 | shuffle 写入所花费的时间 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
远程读取块数 | 远程读取的块数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
远程读取字节数 | 远程读取的字节数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
远程读取到磁盘的字节数 | 从远程读取到本地磁盘的字节数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
本地读取块数 | 本地读取的块数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
本地读取字节数 | 本地读取的字节数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
获取等待时间 | 获取数据(本地和远程)所花费的时间 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
读取记录数 | 读取的记录数 | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
排序时间 | 排序所花费的时间 | Sort |
峰值内存 | 运算符中的峰值内存使用量 | Sort, HashAggregate |
溢出大小 | 运算符中从内存溢出到磁盘的字节数 | Sort, HashAggregate |
聚合构建时间 | 聚合所花费的时间 | HashAggregate, ObjectHashAggregate |
平均哈希探测桶列表迭代次数 | 聚合期间每次查找的平均桶列表迭代次数 | HashAggregate |
构建端数据大小 | 构建的哈希映射大小 | ShuffledHashJoin |
构建哈希映射时间 | 构建哈希映射所花费的时间 | ShuffledHashJoin |
任务提交时间 | 写入成功后提交任务输出所花费的时间 | 基于文件的表上的任何写入操作 |
作业提交时间 | 写入成功后提交作业输出所花费的时间 | 基于文件的表上的任何写入操作 |
发送到 Python worker 的数据 | 发送到 Python worker 的序列化数据字节数 | Python UDFs, Pandas UDFs, Pandas Functions API 和 Python Data Source |
从 Python worker 返回的数据 | 从 Python worker 接收回来的序列化数据字节数 | Python UDFs, Pandas UDFS, Pandas Functions API 和 Python Data Source |
结构化流 (Structured Streaming) 标签页
当以微批处理模式运行结构化流作业时,Web UI 上将提供结构化流标签页。概述页面显示正在运行和已完成查询的一些简要统计信息。此外,您可以检查失败查询的最新异常。有关详细统计信息,请点击表格中的“运行 ID”。

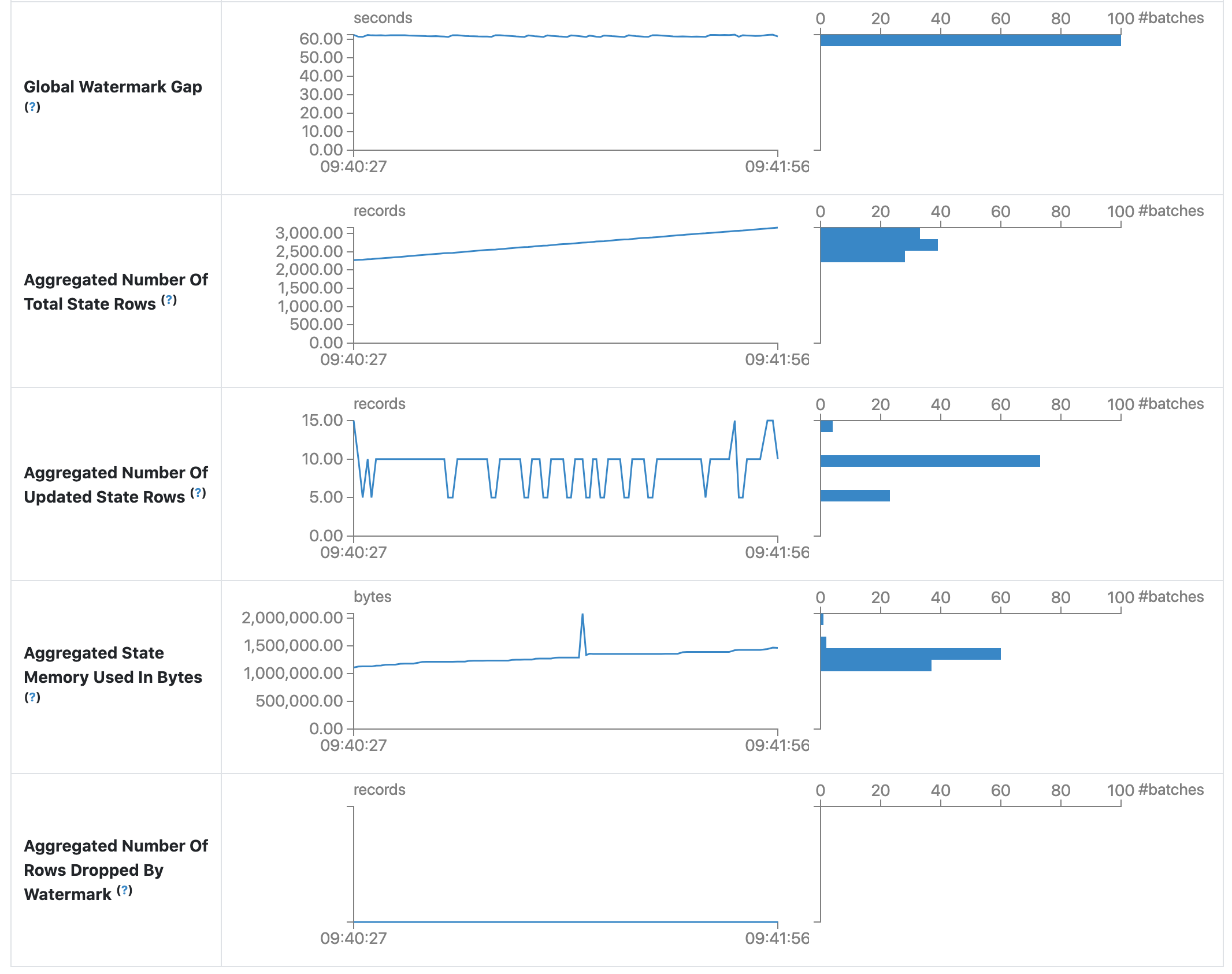
统计页面显示了一些有用的指标,可用于深入了解流式查询的状态。目前,它包含以下指标。
- 输入速率。数据到达的总速率(所有来源的聚合)。
- 处理速率。Spark 处理数据的总速率(所有来源的聚合)。
- 输入行数。在一次触发中处理的记录总数(所有来源的聚合)。
- 批处理持续时间。每个批处理的持续时间。
- 操作持续时间。执行各种操作所花费的时间(以毫秒为单位)。跟踪的操作如下所示。
- addBatch:从源读取微批次输入数据、处理数据并将批次输出写入接收器所花费的时间。这应占据微批次的大部分时间。
- getBatch:准备逻辑查询以从源读取当前微批次输入所花费的时间。
- latestOffset & getOffset:查询此源的最大可用偏移量所花费的时间。
- queryPlanning:生成执行计划所花费的时间。
- walCommit:将偏移量写入元数据日志所花费的时间。
- 全局水印间隔。批处理时间戳与批处理全局水印之间的间隔。
- 状态总行数(聚合)。状态总行数的聚合数量。
- 已更新状态行数(聚合)。已更新状态行数的聚合数量。
- 状态内存使用量(聚合,字节)。聚合的状态内存使用量(以字节为单位)。
- 被水印丢弃的状态行数(聚合)。被水印丢弃的状态行数的聚合数量。
作为早期发布版本,统计页面仍在开发中,并将在未来的版本中进行改进。
流式处理 (Streaming (DStreams)) 标签页
如果应用程序使用带有 DStream API 的 Spark Streaming,Web UI 将包含一个流式处理 (Streaming) 标签页。此标签页显示数据流中每个微批次的调度延迟和处理时间,这对于流式应用程序的故障排除很有用。
JDBC/ODBC 服务器标签页
当 Spark 作为分布式 SQL 引擎运行时,我们可以看到此标签页。它显示有关会话和已提交 SQL 操作的信息。
页面的第一部分显示有关 JDBC/ODBC 服务器的一般信息:启动时间和运行时间。

第二部分包含有关活动会话和已完成会话的信息。
- 连接的用户和 IP。
- 会话 ID,用于访问会话信息的链接。
- 会话的启动时间、结束时间和持续时间。
- 总执行数是此会话中提交的操作数量。

第三部分包含已提交操作的 SQL 统计信息。
- 提交操作的用户。
- 作业 ID,指向作业 (Jobs) 标签页的链接。
- 组 ID,将所有作业分组在一起的查询组 ID。应用程序可以使用此组 ID 取消所有正在运行的作业。
- 操作的启动时间。
- 执行的结束时间,在获取结果之前。
- 操作的关闭时间,在获取结果之后。
- 执行时间是结束时间与启动时间之差。
- 持续时间是关闭时间与启动时间之差。
- 语句是正在执行的操作。
- 进程的状态。
- Started(已启动):第一个状态,当进程开始时。
- Compiled(已编译):已生成执行计划。
- Failed(失败):最终状态,当执行失败或完成时出现错误。
- Canceled(已取消):最终状态,当执行被取消时。
- Finished(已完成):处理完成并等待获取结果。
- Closed(已关闭):最终状态,当客户端关闭语句时。
- 执行计划的详细信息,包括已解析的逻辑计划、已分析的逻辑计划、已优化的逻辑计划和物理计划,或 SQL 语句中的错误。
