结构化流编程指南
- 目录
异步进度跟踪
什么是它?
异步进度跟踪允许流式查询在微批次内异步地、并行地对实际数据处理进行检查点进度,从而减少与维护偏移日志和提交日志相关的延迟。
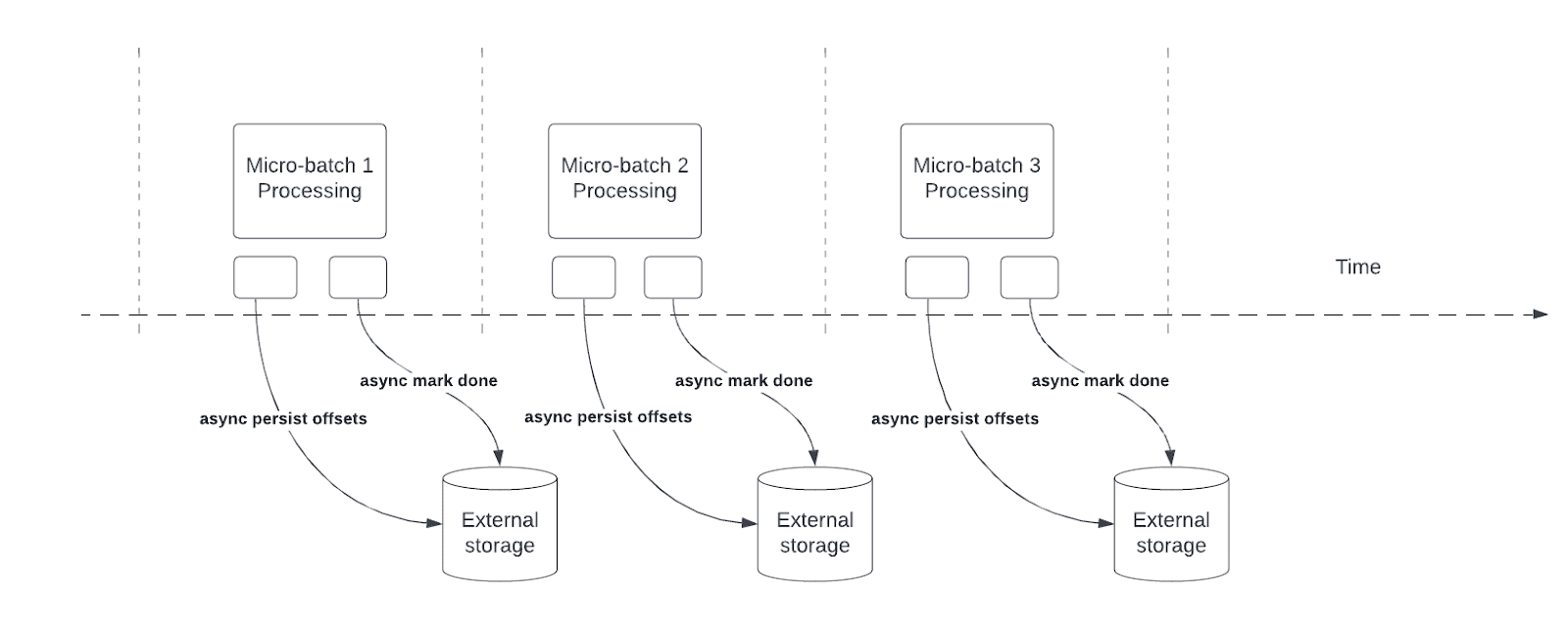
它是如何工作的?
结构化流依赖于持久化和管理偏移量作为查询处理的进度指示器。偏移量管理操作直接影响处理延迟,因为在这些操作完成之前,无法进行数据处理。异步进度跟踪使流式查询能够进行检查点进度,而不受这些偏移量管理操作的影响。
如何使用?
下面的代码片段提供了一个如何使用此功能的示例
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
下表描述了此功能的配置及其相关默认值。
| 选项 | 值 | 默认值 | 描述 |
|---|---|---|---|
| asyncProgressTrackingEnabled | true/false | false | 启用或禁用异步进度跟踪 |
| asyncProgressTrackingCheckpointIntervalMs | 毫秒 | 1000 | 我们提交偏移量和完成提交的间隔 |
限制
此功能的初始版本有以下限制
- 异步进度跟踪仅支持使用 Kafka 接收器的无状态查询
- 借助此异步进度跟踪,不支持端到端精确一次处理,因为批处理的偏移范围在发生故障时可能会发生变化。尽管许多接收器(例如 Kafka 接收器)无论如何都不支持精确一次写入。
关闭此设置
关闭异步进度跟踪可能会导致抛出以下异常
java.lang.IllegalStateException: batch x doesn't exist
驱动程序日志中也可能打印以下错误消息
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
这是由于以下事实造成的:当启用异步进度跟踪时,框架不会像不使用异步进度跟踪时那样为每个批次设置检查点。要解决此问题,只需重新启用“asyncProgressTrackingEnabled”并将“asyncProgressTrackingCheckpointIntervalMs”设置为 0,然后运行流式查询,直到至少处理了两个微批次。现在可以安全地禁用异步进度跟踪,并且重新启动查询应该会正常进行。
持续处理
[实验性]
持续处理是 Spark 2.3 中引入的一种新的实验性流式执行模式,它能够实现低 (~1 毫秒) 端到端延迟,并提供至少一次的容错保证。将其与默认的微批次处理引擎进行比较,后者可以实现精确一次的保证,但最佳延迟约为 100 毫秒。对于某些类型的查询(如下所述),您可以选择以哪种模式执行它们,而无需修改应用程序逻辑(即无需更改 DataFrame/Dataset 操作)。
要在持续处理模式下运行支持的查询,您只需指定一个带有所需检查点间隔作为参数的持续触发器。例如,
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load() \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.trigger(continuous="1 second") \ # only change in query
.start()import org.apache.spark.sql.streaming.Trigger
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start()import org.apache.spark.sql.streaming.Trigger;
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start();1 秒的检查点间隔意味着持续处理引擎将每秒记录查询的进度。生成的检查点采用与微批次引擎兼容的格式,因此任何查询都可以通过任何触发器重新启动。例如,以微批次模式启动的支持查询可以在持续模式下重新启动,反之亦然。请注意,无论何时切换到持续模式,您都将获得至少一次的容错保证。
支持的查询
截至 Spark 2.4,持续处理模式仅支持以下类型的查询。
- 操作:持续模式仅支持类似 map 的 Dataset/DataFrame 操作,即仅支持投影(
select、map、flatMap、mapPartitions等)和选择(where、filter等)。- 支持所有 SQL 函数,但聚合函数(因为尚不支持聚合)、
current_timestamp()和current_date()除外(使用时间进行确定性计算具有挑战性)。
- 支持所有 SQL 函数,但聚合函数(因为尚不支持聚合)、
- 源:
- Kafka 源:支持所有选项。
- Rate 源:适用于测试。持续模式下仅支持
numPartitions和rowsPerSecond选项。
- 接收器:
- Kafka 接收器:支持所有选项。
- Memory 接收器:适用于调试。
- Console 接收器:适用于调试。支持所有选项。请注意,控制台将打印您在持续触发器中指定的每个检查点间隔。
有关它们的更多详细信息,请参阅输入源和输出接收器部分。虽然 Console 接收器适用于测试,但使用 Kafka 作为源和接收器可以最好地观察端到端低延迟处理,因为这使得引擎能够在输入数据在输入主题中可用后的几毫秒内处理数据并将结果提供给输出主题。
注意事项
- 持续处理引擎启动多个长期运行的任务,这些任务持续从源读取数据、处理数据并持续写入接收器。查询所需的任务数量取决于查询可以从源并行读取多少个分区。因此,在启动持续处理查询之前,您必须确保集群中有足够的内核来并行处理所有任务。例如,如果您正在从一个拥有 10 个分区的 Kafka 主题读取数据,那么集群必须至少有 10 个内核才能使查询取得进展。
- 停止持续处理流可能会产生虚假的任务终止警告。这些警告可以安全地忽略。
- 目前没有针对失败任务的自动重试。任何失败都将导致查询停止,需要从检查点手动重新启动。