第四章:错误清除 - PySpark 调试#
PySpark 在分布式环境中执行应用程序,这使得监控和调试这些应用程序变得具有挑战性。跟踪哪些节点正在执行特定代码可能很困难。然而,PySpark 中提供了多种方法来帮助调试。本节将概述如何有效地调试 PySpark 应用程序。
PySpark 以 Spark 作为其底层引擎运行,利用 Spark Connect 服务器或 Py4J(Spark Classic)在 Spark 中提交和计算作业。
在驱动程序侧,PySpark 通过 Spark Connect 服务器或 Py4J(Spark Classic)与 JVM 上的 Spark Driver 交互。当创建并初始化 pyspark.sql.SparkSession 时,PySpark 开始与 Spark Driver 通信。
在执行器侧,Python 工作进程负责执行和管理 Python 原生函数或数据。只有当 PySpark 应用程序需要 Python 和 JVM 之间交互(例如 Python UDF 执行)时,才会启动这些工作进程。它们是按需启动的,例如,当运行 pandas UDF 或 PySpark RDD API 时。
Spark UI#
Python UDF 执行#
调试 PySpark 中的 Python UDF 可以通过简单地添加 print 语句来完成,尽管由于函数在执行器上执行,输出在客户端/驱动程序侧不可见——它们可以在 Spark UI 中查看。例如,如果您有一个正在工作的 Python UDF
[1]:
from pyspark.sql.functions import udf
@udf("integer")
def my_udf(x):
# Do something with x
return x
您可以添加 print 语句进行调试,如下所示
[2]:
@udf("integer")
def my_udf(x):
# Do something with x
print("What's going on?")
return x
spark.range(1).select(my_udf("id")).collect()
[2]:
[Row(my_udf(id)=0)]
输出可以在 Spark UI 的 Executors 选项卡下的 stdout/stderr 中查看。
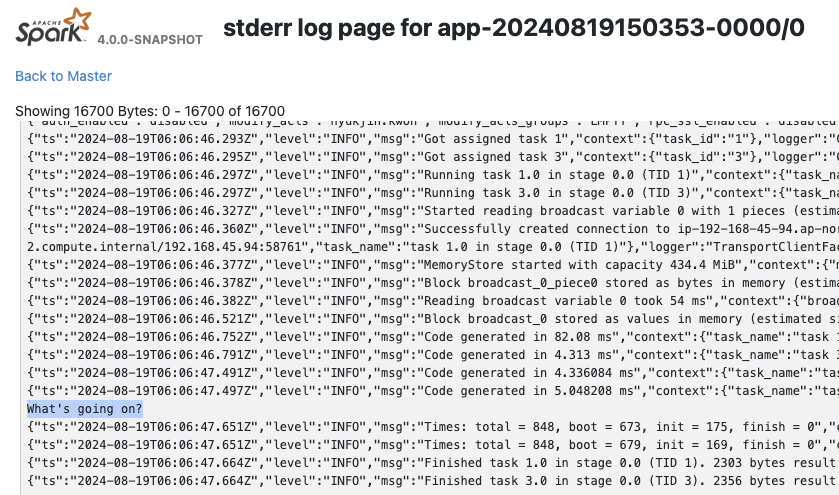
非 Python UDF#
运行非 Python UDF 代码时,通常通过 Spark UI 或使用 DataFrame.explain(True) 进行调试。
例如,下面的代码在大型 DataFrame (df1) 和较小 DataFrame (df2) 之间执行连接
[3]:
df1 = spark.createDataFrame([(x,) for x in range(100)])
df2 = spark.createDataFrame([(x,) for x in range(2)])
df1.join(df2, "_1").explain()
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [_1#6L]
+- SortMergeJoin [_1#6L], [_1#8L], Inner
:- Sort [_1#6L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(_1#6L, 200), ENSURE_REQUIREMENTS, [plan_id=41]
: +- Filter isnotnull(_1#6L)
: +- Scan ExistingRDD[_1#6L]
+- Sort [_1#8L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(_1#8L, 200), ENSURE_REQUIREMENTS, [plan_id=42]
+- Filter isnotnull(_1#8L)
+- Scan ExistingRDD[_1#8L]
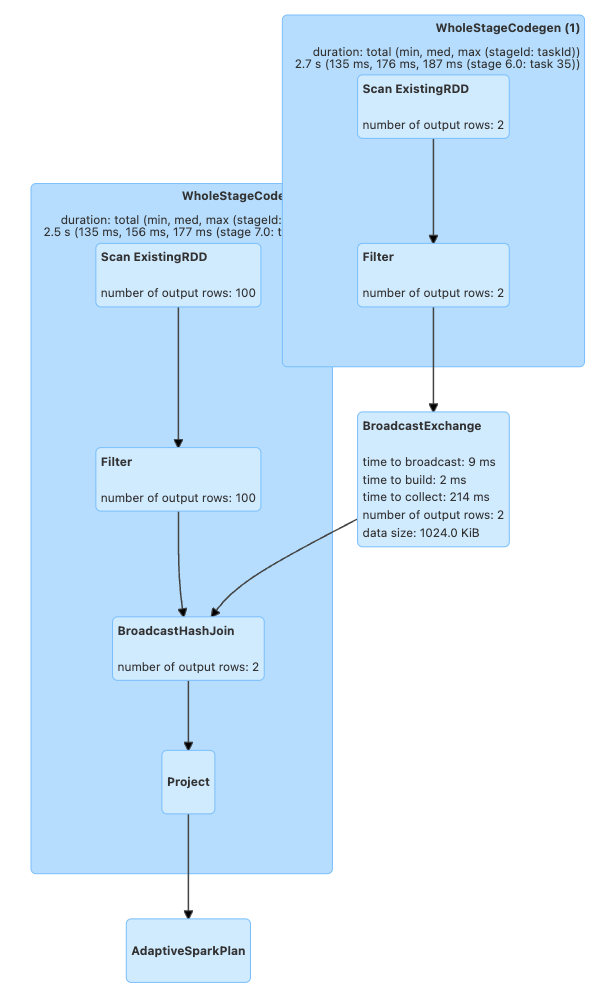
使用 DataFrame.explain 可以显示物理计划,展示连接将如何执行。这些物理计划代表了整个执行过程中的各个步骤。在这里,它交换(即 shuffle)数据并执行排序合并连接。
通过此方法检查计划的生成方式后,用户可以优化他们的查询。例如,因为 df2 非常小,所以可以将其广播到执行器并消除 shuffle
[4]:
from pyspark.sql.functions import broadcast
df1.join(broadcast(df2), "_1").explain()
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Project [_1#6L]
+- BroadcastHashJoin [_1#6L], [_1#8L], Inner, BuildRight, false
:- Filter isnotnull(_1#6L)
: +- Scan ExistingRDD[_1#6L]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [plan_id=71]
+- Filter isnotnull(_1#8L)
+- Scan ExistingRDD[_1#8L]
可以看出,shuffle 被移除了,并且它执行了广播哈希连接
这些优化也可以在执行后在 Spark UI 的 SQL / DataFrame 选项卡中可视化。
[5]:
df1.join(df2, "_1").collect()
[5]:
[Row(_1=0), Row(_1=1)]

[6]:
df1.join(broadcast(df2), "_1").collect()
[6]:
[Row(_1=0), Row(_1=1)]
使用 top 和 ps 进行监控#
在驱动程序侧,您可以从 PySpark shell 获取进程 ID 以监控资源
[7]:
import os; os.getpid()
[7]:
23976
[8]:
%%bash
ps -fe 23976
UID PID PPID C STIME TTY TIME CMD
502 23976 21512 0 12:06PM ?? 0:02.30 /opt/miniconda3/envs/python3.11/bin/python -m ipykernel_launcher -f /Users/hyukjin.kwon/Library/Jupyter/runtime/kernel-c8eb73ef-2b21-418e-b770-92b946454606.json
在执行器侧,您可以使用 grep 查找 Python 工作进程的进程 ID 和资源,因为它们是从 pyspark.daemon fork 出来的。
[9]:
%%bash
ps -fe | grep pyspark.daemon | head -n 5
502 23989 23981 0 12:06PM ?? 0:00.59 python3 -m pyspark.daemon pyspark.worker
502 23990 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
502 23991 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
502 23992 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
502 23993 23989 0 12:06PM ?? 0:00.19 python3 -m pyspark.daemon pyspark.worker
通常,用户利用 top 和识别出的 PID 来监控 PySpark 中 Python 进程的内存使用情况。
使用 PySpark Profilers#
内存分析器#
为了调试驱动程序侧,用户通常可以使用大多数现有的 Python 工具,例如 memory_profiler,它们允许您逐行检查内存使用情况。如果您的驱动程序不在另一台机器(例如,YARN 集群模式)上运行,您可以使用内存分析器来调试驱动程序侧的内存使用情况。例如
[10]:
%%bash
echo "from pyspark.sql import SparkSession
#===Your function should be decorated with @profile===
from memory_profiler import profile
@profile
#=====================================================
def my_func():
session = SparkSession.builder.getOrCreate()
df = session.range(10000)
return df.collect()
if __name__ == '__main__':
my_func()" > profile_memory.py
python -m memory_profiler profile_memory.py 2> /dev/null
Filename: profile_memory.py
Line # Mem usage Increment Occurrences Line Contents
=============================================================
4 80.6 MiB 80.6 MiB 1 @profile
5 #=====================================================
6 def my_func():
7 79.0 MiB -1.7 MiB 1 session = SparkSession.builder.getOrCreate()
8 80.1 MiB 1.1 MiB 1 df = session.range(10000)
9 84.1 MiB 4.0 MiB 1 return df.collect()
它能正确显示哪行代码消耗了多少内存。
Python 和 Pandas UDF#
注意:本节适用于 Spark 4.0
PySpark 为 Python/Pandas UDF 提供了远程 memory_profiler。它可以在带有行号的编辑器(如 Jupyter notebooks)中使用。通过将运行时 SQL 配置 spark.sql.pyspark.udf.profiler 设置为 memory 可以启用基于 SparkSession 的内存分析器
[11]:
from pyspark.sql.functions import pandas_udf
df = spark.range(10)
@pandas_udf("long")
def add1(x):
return x + 1
spark.conf.set("spark.sql.pyspark.udf.profiler", "memory")
added = df.select(add1("id"))
spark.profile.clear()
added.collect()
spark.profile.show(type="memory")
============================================================
Profile of UDF<id=16>
============================================================
Filename: /var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/885006762.py
Line # Mem usage Increment Occurrences Line Contents
=============================================================
5 1472.6 MiB 1472.6 MiB 10 @pandas_udf("long")
6 def add1(x):
7 1473.9 MiB 1.3 MiB 10 return x + 1
UDF ID 可以在查询计划中看到,例如,在 ArrowEvalPython 中显示的 add1(...)#16L。
[12]:
added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#19L AS add1(id)#17L]
+- ArrowEvalPython [add1(id#14L)#16L], [pythonUDF0#19L], 200
+- *(1) Range (0, 10, step=1, splits=16)
性能分析器#
注意:本节适用于 Spark 4.0
Python 分析器 是 Python 自身有用的内置功能。要在驱动程序侧使用它,您可以像使用常规 Python 程序一样使用它,因为 PySpark 在驱动程序侧就是一个常规 Python 进程,除非您在另一台机器(例如,YARN 集群模式)上运行您的驱动程序。
[13]:
%%bash
echo "from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.range(10).collect()" > app.py
python -m cProfile -s cumulative app.py 2> /dev/null | head -n 20
549275 function calls (536745 primitive calls) in 3.447 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
2 0.000 0.000 3.448 1.724 app.py:1(<module>)
792/1 0.005 0.000 3.447 3.447 {built-in method builtins.exec}
128 0.000 0.000 2.104 0.016 socket.py:692(readinto)
128 2.104 0.016 2.104 0.016 {method 'recv_into' of '_socket.socket' objects}
124 0.000 0.000 2.100 0.017 java_gateway.py:1015(send_command)
125 0.001 0.000 2.099 0.017 clientserver.py:499(send_command)
138 0.000 0.000 2.097 0.015 {method 'readline' of '_io.BufferedReader' objects}
55 0.000 0.000 1.622 0.029 java_gateway.py:1313(__call__)
95 0.001 0.000 1.360 0.014 __init__.py:1(<module>)
1 0.000 0.000 1.359 1.359 session.py:438(getOrCreate)
1 0.000 0.000 1.311 1.311 context.py:491(getOrCreate)
1 0.000 0.000 1.311 1.311 context.py:169(__init__)
1 0.000 0.000 0.861 0.861 context.py:424(_ensure_initialized)
1 0.001 0.001 0.861 0.861 java_gateway.py:39(launch_gateway)
8 0.840 0.105 0.840 0.105 {built-in method time.sleep}
Python/Pandas UDF#
注意:本节适用于 Spark 4.0
PySpark 为 Python/Pandas UDF 提供了远程 Python 分析器。不支持输入/输出为迭代器的 UDF。通过将运行时 SQL 配置 spark.sql.pyspark.udf.profiler 设置为 perf,可以启用基于 SparkSession 的性能分析器。示例如下所示。
[14]:
import io
from contextlib import redirect_stdout
from pyspark.sql.functions import pandas_udf
df = spark.range(10)
@pandas_udf("long")
def add1(x):
return x + 1
added = df.select(add1("id"))
spark.conf.set("spark.sql.pyspark.udf.profiler", "perf")
spark.profile.clear()
added.collect()
# Only show top 10 lines
output = io.StringIO()
with redirect_stdout(output):
spark.profile.show(type="perf")
print("\n".join(output.getvalue().split("\n")[0:20]))
============================================================
Profile of UDF<id=22>
============================================================
2130 function calls (2080 primitive calls) in 0.003 seconds
Ordered by: internal time, cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
10 0.001 0.000 0.003 0.000 common.py:62(new_method)
10 0.000 0.000 0.000 0.000 {built-in method _operator.add}
10 0.000 0.000 0.002 0.000 base.py:1371(_arith_method)
10 0.000 0.000 0.001 0.000 series.py:389(__init__)
20 0.000 0.000 0.000 0.000 _ufunc_config.py:33(seterr)
10 0.000 0.000 0.001 0.000 series.py:6201(_construct_result)
10 0.000 0.000 0.000 0.000 cast.py:1605(maybe_cast_to_integer_array)
10 0.000 0.000 0.000 0.000 construction.py:517(sanitize_array)
10 0.000 0.000 0.002 0.000 series.py:6133(_arith_method)
10 0.000 0.000 0.000 0.000 managers.py:1863(from_array)
10 0.000 0.000 0.000 0.000 array_ops.py:240(arithmetic_op)
510 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance}
UDF ID 可以在查询计划中看到,例如,在下面的 ArrowEvalPython 中显示的 add1(...)#22L。
[15]:
added.explain()
== Physical Plan ==
*(2) Project [pythonUDF0#25L AS add1(id)#23L]
+- ArrowEvalPython [add1(id#20L)#22L], [pythonUDF0#25L], 200
+- *(1) Range (0, 10, step=1, splits=16)
我们可以使用预先注册的渲染器来渲染结果,如下所示。
[16]:
spark.profile.render(id=2, type="perf") # renderer="flameprof" by default

显示堆栈跟踪#
注意:本节适用于 Spark 4.0
默认情况下,JVM 堆栈跟踪和 Python 内部回溯是隐藏的,特别是在 Python UDF 执行中。例如,
[17]:
from pyspark.sql.functions import udf
spark.range(1).select(udf(lambda x: x / 0)("id")).collect()
PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3806637820.py", line 3, in <lambda>
ZeroDivisionError: division by zero
要显示整个内部堆栈跟踪,用户可以分别启用 spark.sql.execution.pyspark.udf.simplifiedTraceback.enabled 和 spark.sql.pyspark.jvmStacktrace.enabled。
[18]:
spark.conf.set("spark.sql.execution.pyspark.udf.simplifiedTraceback.enabled", False)
spark.conf.set("spark.sql.pyspark.jvmStacktrace.enabled", False)
spark.range(1).select(udf(lambda x: x / 0)("id")).collect()
PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1898, in main
process()
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1890, in process
serializer.dump_stream(out_iter, outfile)
File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 224, in dump_stream
self.serializer.dump_stream(self._batched(iterator), stream)
File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 145, in dump_stream
for obj in iterator:
File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 213, in _batched
for item in iterator:
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1798, in mapper
result = tuple(f(*[a[o] for o in arg_offsets]) for arg_offsets, f in udfs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 1798, in <genexpr>
result = tuple(f(*[a[o] for o in arg_offsets]) for arg_offsets, f in udfs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 114, in <lambda>
return args_kwargs_offsets, lambda *a: func(*a)
^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/util.py", line 145, in wrapper
return f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^
File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 739, in profiling_func
ret = f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3570641234.py", line 3, in <lambda>
ZeroDivisionError: division by zero
[19]:
spark.conf.set("spark.sql.execution.pyspark.udf.simplifiedTraceback.enabled", True)
spark.conf.set("spark.sql.pyspark.jvmStacktrace.enabled", True)
spark.range(1).select(udf(lambda x: x / 0)("id")).collect()
PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3514597595.py", line 3, in <lambda>
ZeroDivisionError: division by zero
JVM stacktrace:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 15 in stage 13.0 failed 1 times, most recent failure: Lost task 15.0 in stage 13.0 (TID 161) (ip-192-168-45-94.ap-northeast-2.compute.internal executor driver): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/var/folders/qm/mlwmy16n5xx66ldgzmptzlc40000gp/T/ipykernel_23976/3514597595.py", line 3, in <lambda>
ZeroDivisionError: division by zero
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:531)
at org.apache.spark.sql.execution.python.BasePythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:103)
at org.apache.spark.sql.execution.python.BasePythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:86)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:485)
...
更多详情请参阅 堆栈跟踪。
IDE 调试#
在驱动程序侧,无需额外步骤即可使用 IDE 调试 PySpark 应用程序。请参阅以下指南
在执行器侧,设置远程调试器需要几个步骤。请参阅以下指南