转换并应用函数#
有许多 API 允许用户对 Spark 上的 pandas DataFrame 应用函数,例如 DataFrame.transform()、DataFrame.apply()、DataFrame.pandas_on_spark.transform_batch()、DataFrame.pandas_on_spark.apply_batch()、Series.pandas_on_spark.transform_batch() 等。每个 API 都有独特的用途,并且在内部工作方式不同。本节描述了它们之间的区别,这些区别常常让用户感到困惑。
transform 和 apply#
DataFrame.transform() 和 DataFrame.apply() 的主要区别在于,前者要求返回与输入相同的长度,而后者则没有此要求。请看下面的例子
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return pser + 1 # should always return the same length as input.
...
>>> psdf.transform(pandas_plus)
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
>>> def pandas_plus(pser):
... return pser[pser % 2 == 1] # allows an arbitrary length
...
>>> psdf.apply(pandas_plus)
在这种情况下,每个函数都接收一个 pandas Series,并且 Spark 上的 pandas API 会以分布式方式计算这些函数,如下所示。
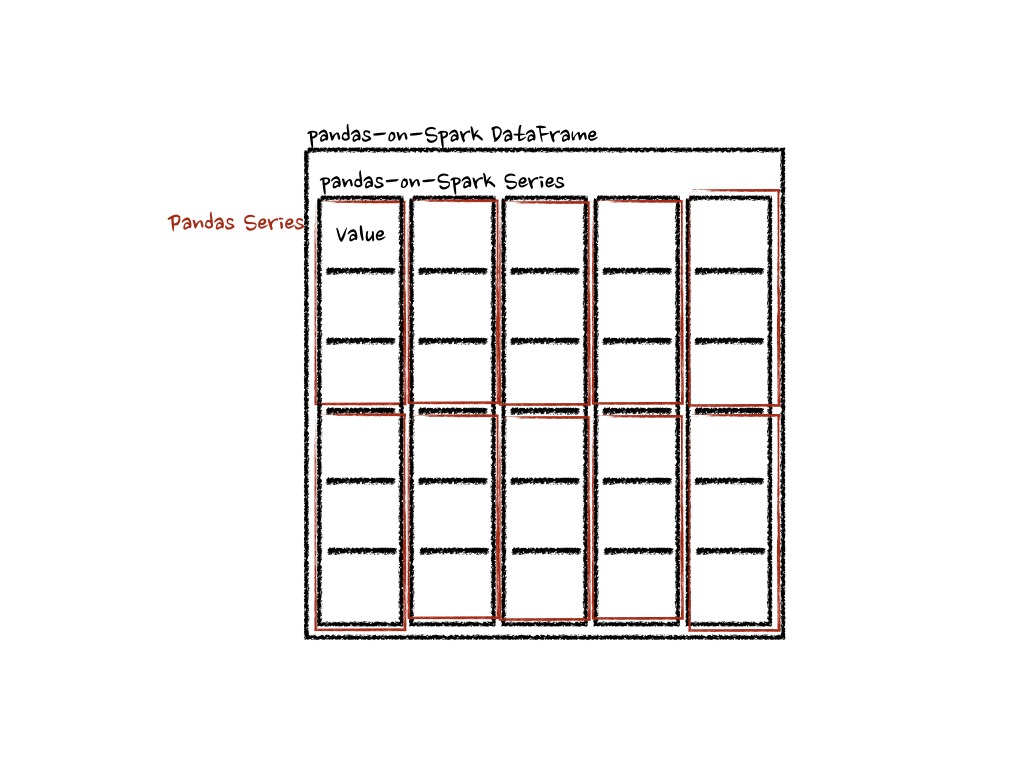
在“列”轴的情况下,函数将每一行作为 pandas Series 处理。
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return sum(pser) # allows an arbitrary length
...
>>> psdf.apply(pandas_plus, axis='columns')
上面的例子计算了每一行的总和作为一个 pandas Series。请看下面

在上面的例子中,为了简化,没有使用类型提示,但鼓励使用它们以避免性能损失。请参考 API 文档。
pandas_on_spark.transform_batch 和 pandas_on_spark.apply_batch#
在 DataFrame.pandas_on_spark.transform_batch()、DataFrame.pandas_on_spark.apply_batch()、Series.pandas_on_spark.transform_batch() 等 API 中,batch 后缀表示 Spark 上的 pandas DataFrame 或 Series 中的每个数据块(chunk)。这些 API 会切分 Spark 上的 pandas DataFrame 或 Series,然后将给定的函数应用于以 pandas DataFrame 或 Series 作为输入和输出的数据块。请看下面的例子
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pdf):
... return pdf + 1 # should always return the same length as input.
...
>>> psdf.pandas_on_spark.transform_batch(pandas_plus)
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pdf):
... return pdf[pdf.a > 1] # allow arbitrary length
...
>>> psdf.pandas_on_spark.apply_batch(pandas_plus)
这两个例子中的函数都将 pandas DataFrame 作为 Spark 上的 pandas DataFrame 的一个数据块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将这些 pandas DataFrame 组合成一个 Spark 上的 pandas DataFrame。
请注意,DataFrame.pandas_on_spark.transform_batch() 有长度限制——输入和输出的长度必须相同——而 DataFrame.pandas_on_spark.apply_batch() 则没有此限制。然而,重要的是要知道当 DataFrame.pandas_on_spark.transform_batch() 返回一个 Series 时,其输出属于同一个 DataFrame,并且可以通过不同 DataFrame 之间的操作避免数据混洗(shuffle)。对于 DataFrame.pandas_on_spark.apply_batch(),其输出总是被视为属于一个新的不同 DataFrame。另请参阅 不同 DataFrame 上的操作 了解更多详情。
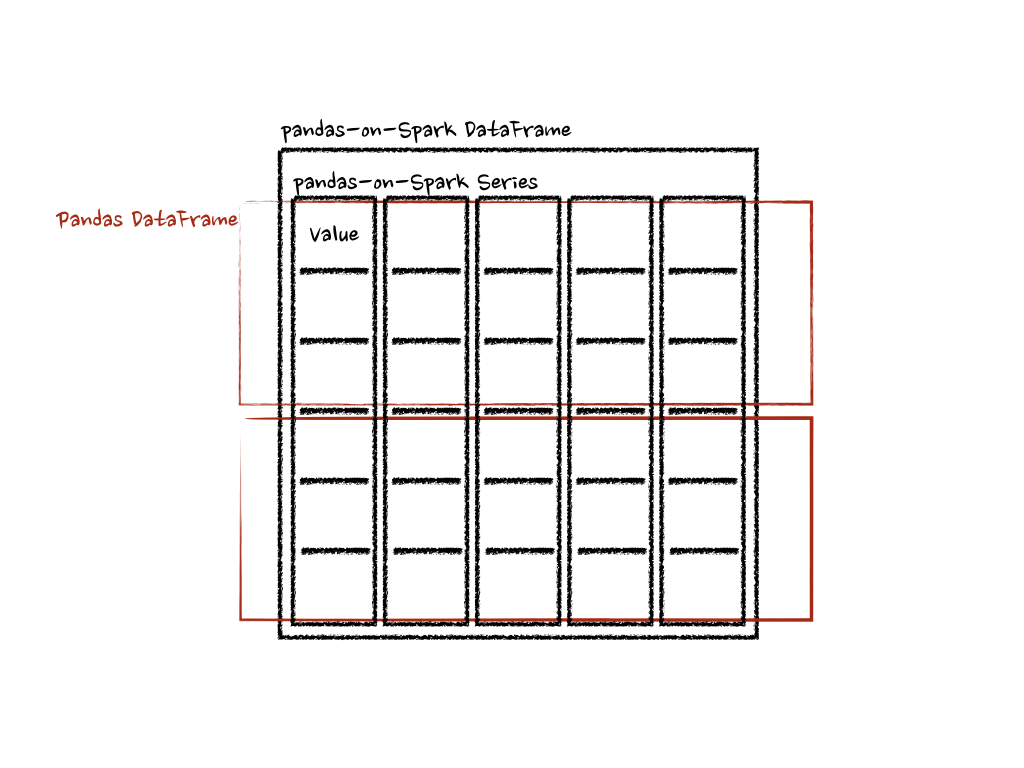
对于 Series.pandas_on_spark.transform_batch(),它与 DataFrame.pandas_on_spark.transform_batch() 类似;但它将 pandas Series 作为 Spark 上的 pandas Series 的一个数据块。
>>> psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return pser + 1 # should always return the same length as input.
...
>>> psdf.a.pandas_on_spark.transform_batch(pandas_plus)
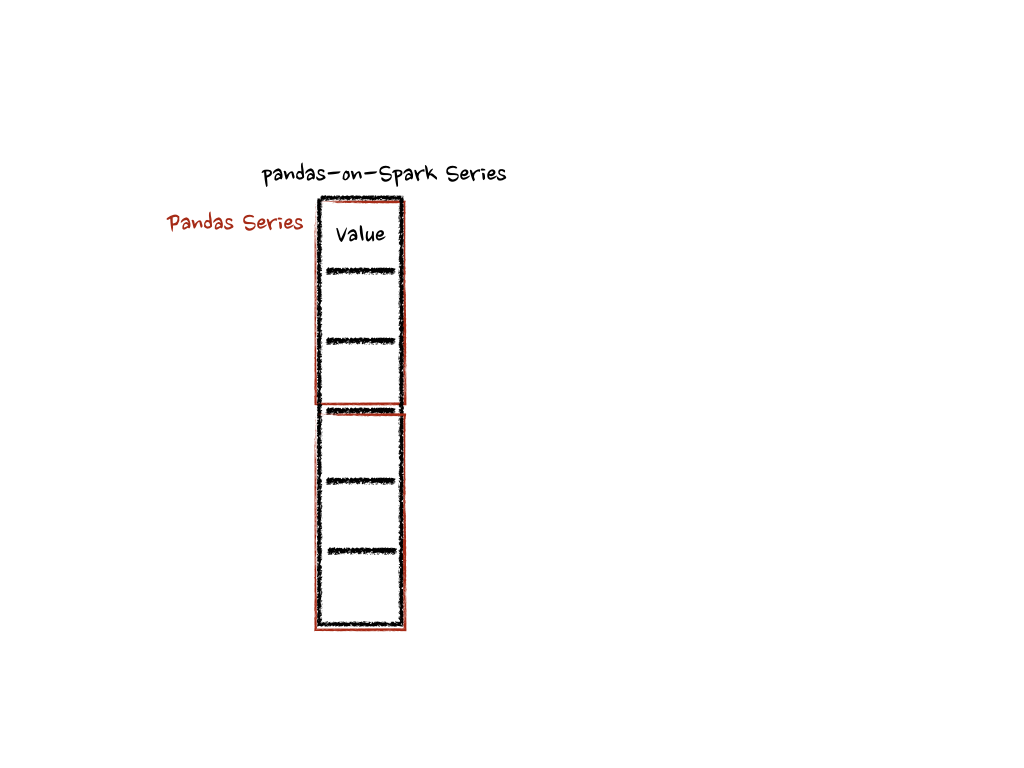
在内部,Spark 上的 pandas Series 的每个批次都会被分割成多个 pandas Series,并且每个函数都会在上面进行计算,如下所示
还有更多细节,例如类型推断以及如何防止其性能损失。请参考 API 文档。